

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Configure a Service Account & IAM permissions
/ 20
Configure credential file for a Service Account
/ 20
Modify the application to save text from images to Cloud Storage
/ 20
Modify the application to translate text using the Language API
/ 20
Query the BigQuery table
/ 20
チャレンジラボでは、シナリオと一連のタスクが提供されます。手順ガイドに沿って進める形式ではなく、コース内のラボで習得したスキルを駆使して、ご自身でタスクを完了していただきます。タスクが適切に完了したかどうかは、このページに表示される自動スコアリング システムで確認できます。
チャレンジラボは、Google Cloud の新しいコンセプトについて学習するためのものではありません。デフォルト値を変更する、エラー メッセージを読み調査を行ってミスを修正するなど、習得したスキルを応用する能力が求められます。
100% のスコアを達成するには、制限時間内に全タスクを完了する必要があります。
このラボは、「Google Cloud での ML の API の使用」コースに登録している受講者を対象としています。準備が整ったらチャレンジを開始しましょう。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

あなたは Jooli Inc. のアナリティクス チームのメンバーとして新たな役割を担うことになりました。会社の ML プロジェクトにおいてデータセットの開発と評価を支援することが求められています。主なタスクとして、さまざまなデータセットの準備、クリーニング、分析が含まれます。
これらのタスクのスキルや知識があるという前提のため、手順ガイドは提供されません。
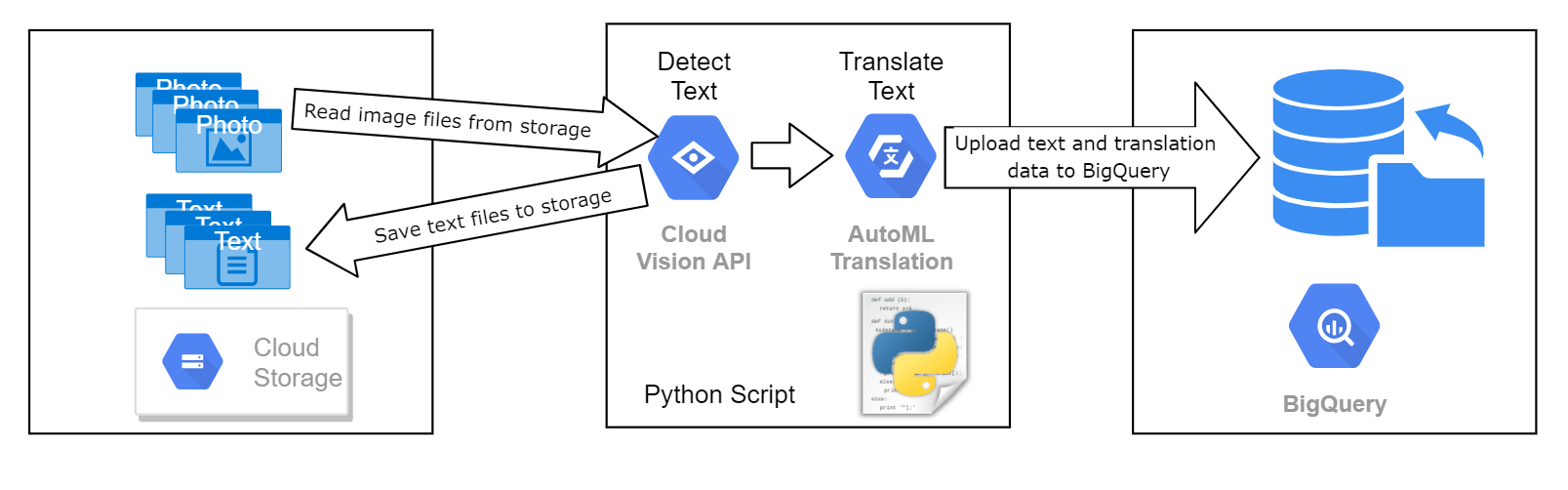
サイネージの複数の画像を分析して、画像内のテキストを抽出、翻訳するプロセスを開発するように依頼されました。抽出したテキスト情報は、ML プロジェクトの一環として、画像の分類に役立てるために使用されます。なお、このプロジェクトでは、モデルのトレーニングと評価にその画像データセットが使用されます。すべての画像にはテキストが含まれますが、テキストの言語はさまざまです。画像は Cloud Storage バケットに保存され、いつでも利用可能な状態です。
Python スクリプトを使用して、各画像ファイルを Google Vision API に送信して処理し、画像内のテキストを特定します。各画像から抽出したテキストは、それぞれ別のファイルとして、Cloud Storage に保存しなおす必要があります。テキストのロケールが
次の図にプロセスの概略を示します。
処理されたテキスト データは必ず、プロジェクト(image_classification_dataset)のデータセットにある既存の BigQuery テーブル(image_text_detail)に書き出されます。
チームメンバーの 1 人が、以前 Natural Language API を使用して一連のテキスト ファイルを処理するのに使用した Python スクリプトをベースにして、画像を処理するためのコードの編集に取り掛かっていました。このメンバーが別のプロジェクトに異動してしまったので、あなたがこのタスクを完了させなければなりません。
スクリプトの編集はほとんど完了しており、引き継いだバージョンでは、ストレージ バケットにアクセスでき、画像ファイルが検出されるたびに反復処理が行われるようになっています。しかし、各画像からテキストを検出して、そのテキストを Translation API に送信するための API 呼び出しがまだ実装されていません。
手元には、作業中の Python スクリプトのコピーと、ラボ プロジェクト ID の名前が付けられた Cloud Storage バケットに保存されているサンプル画像セットがあります。
チームメンバーは、スクリプトの完成していない箇所を特定し、作成する必要がある API 呼び出しについてコメントを残してくれています。スクリプトには完成していないところが 3 箇所あります。この未完成部分を完了させ、適切な ML の API 呼び出しを作成する必要があります。未完成部分にはすべて、先頭に # TBD: というコメントが付いています。
最後の行には、結果データを BigQuery にアップロードするコードが記述されていますが、この行はコメント文字で無効になっています。スクリプトの他の部分が問題なく機能することを確認したら、コメント文字を削除して最後の行を有効にします。
スクリプトを編集する前に、環境を準備する必要があります。適切な権限を持つサービス アカウントを作成し、そのアカウントの認証情報ファイルをダウンロードします。サービス アカウントの認証情報を取得すると、Python スクリプトを変更し、それを使用して画像ファイルを処理することができます。
課題を完了するには、すべての画像に対して、最初に抽出したテキスト、言語、翻訳済みのテキストデータを BigQuery テーブル(image_text_detail)に読み込む必要があります。この処理を行うコードはスクリプトの最後の行に記述されています。この行を有効にするには、コメント文字を削除する必要があります。
更新した Python スクリプトを使用して、画像ファイルを処理し、データを BigQuery にアップロードできたら、次の BigQuery クエリを実行して、画像データが正常に処理されることを確認する必要があります。
このクエリを実行すると、サンプル画像セットから検出された、それぞれの言語タイプごとのサイネージの数が報告されます。
analyze-images-v2.py ファイルを、作成された Cloud Storage バケットから Cloud Shell にコピーします。
プロジェクト バケットに保存した画像ファイルからテキストを抽出するよう Python スクリプトを変更して、各ファイルのテキストデータをテキスト ファイルに保存して、同じバケットに書き戻す必要があります。スクリプトには、API にアクセスするためのコードを追加する必要がある箇所に # TBD というコメントが付いています。
Cloud Vision API を使用して画像ファイルからテキストデータを抽出するようにスクリプトの最初の部分を変更します。変更したら、その時点でスクリプトを実行し、処理が正しく進んでいることを確認します。
次に、Vision API で検出された
ヒント 1: 認証情報ファイルの詳細を提供するために、環境変数を設定する必要があります。認証情報ファイルは、Python スクリプトが Google Cloud API にアクセスするときに使用されます。
ヒント 2: Vision API クライアントの document_text_detection API 呼び出しの詳細については、Vision API クライアントの Python API ドキュメント リファレンス ページで確認できます。また、Vision API アノテーション レスポンス オブジェクトの詳細については、Vision API オブジェクトの Python API ドキュメント リファレンス ページで確認できます。
ヒント 3: Translation API クライアントの Translate API 呼び出しの詳細については、Translation V2 API クライアントの Python API ドキュメントを参照してください。
サイネージの複数の画像を分析し、それらの画像内のテキストを抽出して翻訳するプロセスの開発が完了しました。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 8 月 30 日
ラボの最終テスト日: 2024 年 8 月 30 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください