

准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Install packages, and configure the notebook.
/ 15
Prepare the dataset
/ 15
Use token based search
/ 15
Create an index endpoint and sparse embedding index in Vector Search
/ 15
Create the hybrid index and deploy it to the Endpoint
/ 20
Run a hybrid query
/ 20
Vertex AI Vector Search 支援混合型搜尋,這是資訊檢索 (IR) 領域常用的架構模式,結合語意搜尋與關鍵字搜尋 (也稱為「詞元型搜尋」)。開發人員可以運用混合型搜尋,結合兩種做法的優勢,有效提高搜尋品質。
這個實驗室會說明如何使用 Google 商品資料集,對產品執行混合型搜尋。完成之後,您會比較混合型搜尋與詞元型搜尋的結果。
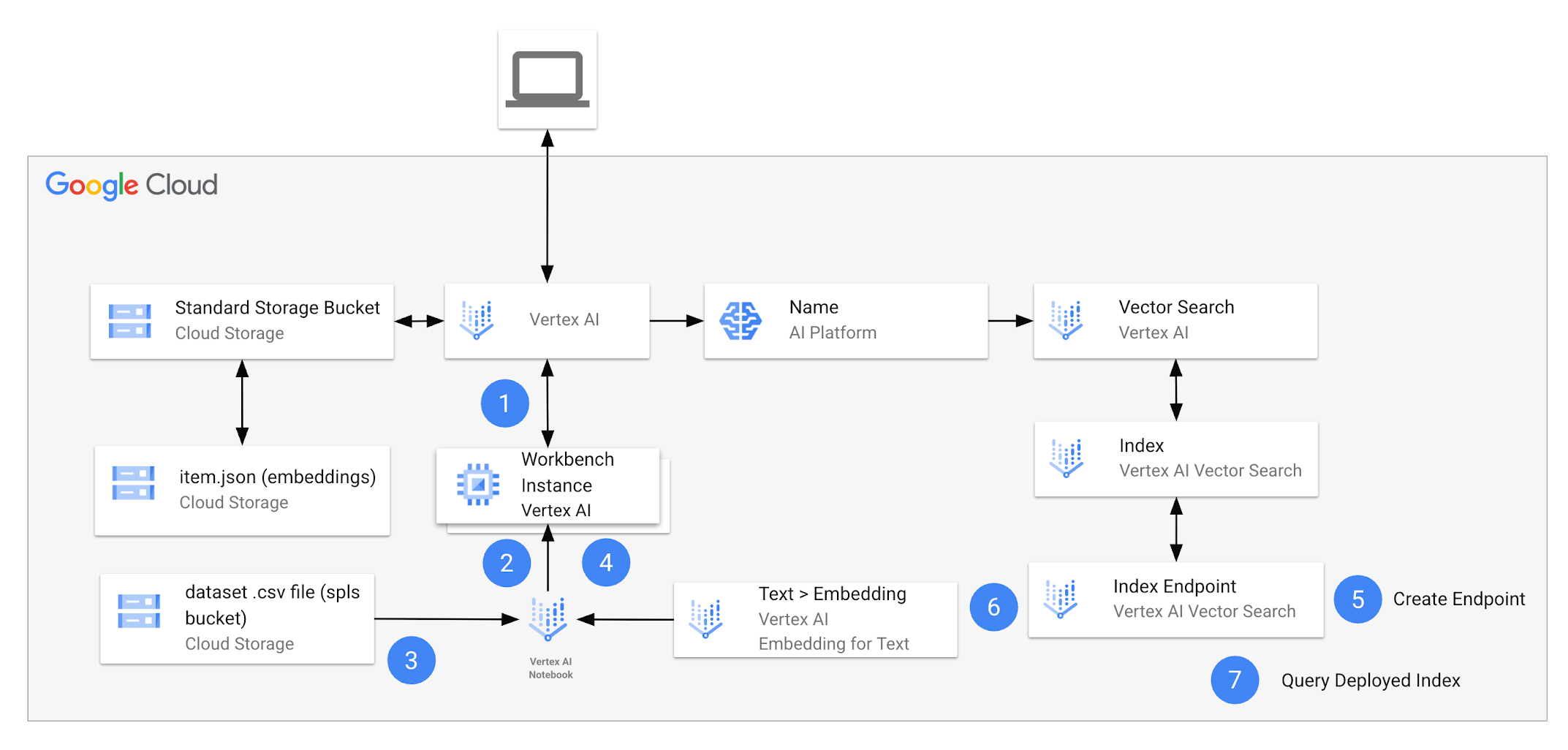
啟動實驗室時,環境中會有下方圖表顯示的資源。
完成實驗室活動時,您會運用這個架構執行多項工作。
下表詳細說明個別工作與實驗室架構的關聯。
| 有編號的工作 | 詳細資料 |
|---|---|
| 1. | 在 Vertex AI Workbench 開啟筆記本,然後選取核心。 |
| 2. |
安裝套件,並為專案設定筆記本: 您會使用 Google Gen AI SDK,透過 Developer API 和 Vertex AI 使用文字嵌入模型。您需要安裝 Python 程式庫,並在整個實驗室活動中參考。您也需要設定筆記本,以便存取專案中的資源,例如實驗室啟動時提供的 Cloud Storage bucket。 |
| 3. |
準備資料集: 在這項工作,您會下載內含 Google 商品品項的資料集 .csv 檔案,並新增至 Pandas DataFrame。 |
| 4. |
執行詞元型搜尋: 您會訓練向量化工具,該模型會從文字生成稀疏嵌入,讓您套用至資料集。 |
| 5. |
建立索引端點: 您必須建立索引端點,才能在 Vertex AI Vector Search 使用混合型搜尋。 |
| 6. |
建立混合型查詢索引並部署至端點: 您會使用「text-embedding-005」模型,為資料集項目生成稠密嵌入,然後結合稀疏嵌入來建立混合型索引。完成之後,您會將混合型索引部署至端點。 |
| 7. |
執行混合型查詢: 部署索引之後,您必須先建立 HybridQuery 物件,封裝查詢文字的稀疏嵌入,接著才能執行查詢。 |
開始這個實驗室之前,您應已熟悉下列概念:
這個實驗室的內容如下:
請詳閱以下操作說明。實驗室活動會計時,且中途無法暫停。點選「Start Lab」後就會開始計時,顯示可使用 Google Cloud 資源的時間。
您將在真正的雲端環境完成實作實驗室活動,而不是模擬或示範環境。為此,我們會提供新的暫時憑證,供您在實驗室活動期間登入及存取 Google Cloud。
為了順利完成這個實驗室,請先確認:
點選「Start Lab」按鈕。如果實驗室會產生費用,畫面上會出現選擇付款方式的對話方塊。左側的「Lab Details」窗格會顯示下列項目:
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也能按一下滑鼠右鍵,選取「在無痕視窗中開啟連結」。
接著,實驗室會啟動相關資源,並開啟另一個分頁,顯示「登入」頁面。
提示:您可以在不同的視窗中並排開啟分頁。
如有必要,請將下方的 Username 貼到「登入」對話方塊。
您也可以在「Lab Details」窗格找到 Username。
點選「下一步」。
複製下方的 Password,並貼到「歡迎使用」對話方塊。
您也可以在「Lab Details」窗格找到 Password。
點選「下一步」。
按過後續的所有頁面:
Google Cloud 控制台稍後會在這個分頁開啟。

前往 Google Cloud 控制台,依序點按「導覽選單」圖示 
找出
Workbench 執行個體的 JupyterLab 介面會在新瀏覽器分頁開啟。
1. 關閉 JupyterLab 的瀏覽器分頁,回到 Workbench 首頁。
2. 勾選執行個體名稱旁的核取方塊,然後點按「重設」。
3. 「開啟 JupyterLab」按鈕再次啟用後,等待一分鐘,然後點按「開啟 JupyterLab」。
開啟
出現「Select Kernel」對話方塊時,從可用核心清單中選取「Python 3」。
為開始使用筆記本,請從第 1 節「建立稀疏嵌入」著手。
在這項工作,您會安裝必要的 Python 套件、重新啟動核心執行階段、將筆記本設為使用您的專案和區域,並匯入程式庫。
填寫工作 2 安裝套件並設定筆記本中的儲存格。
如未自動填入,請將「專案 ID」設為「
點選「Check my progress」,確認目標已達成。
在這項工作,您會下載並準備資料集 .csv 檔案,以便在筆記本使用。
點選「Check my progress」,確認目標已達成。
在這項工作,您會建立稀疏嵌入,並在資料集搜尋「Chrome Dino Pin」商品,取得向量值和維度。您也會擷取資料集內其他產品的值。接著,您會將這些資料儲存至 Workbench 中的 items.json 檔案,並將這個檔案複製到 Cloud Storage bucket。
點選「Check my progress」,確認目標已達成。
請前往筆記本的第 2 節,開始使用混合型搜尋。
首先,您會在第 5 項工作建立索引端點。
點選「Check my progress」,確認目標已達成。
在這項工作,您會擷取文字嵌入模型,針對一項商品執行稠密嵌入的範例查詢,再針對所有商品執行。接著,您會將這些資料儲存在 items.json 檔案,然後依據該檔案建立混合型索引,並將索引部署至端點。
在等待混合型索引部署期間,您可以依序前往「Vertex AI」>「Vector Search」>「索引端點」查看部署進度。
您也可以花一些時間查看這項示範。這項示範提供實際範例,讓您瞭解 Vector Search 的運作方式、認識語意和混合型搜尋,以及查看實際的重新排名情形。只要提交動物、植物、電子商務商品或其他物品的簡短說明,Vector Search 就能完成剩餘步驟!
點選「Check my progress」,確認目標已達成。
在這項工作,您會使用剛剛部署的混合型索引執行混合型查詢,並比較這項查詢與稀疏嵌入查詢的結果。
點選「Check my progress」,確認目標已達成。
在這個實驗室,您學會如何在 Vertex AI Vector Search 使用混合型搜尋,包括建立並部署混合型搜尋索引,以及查詢索引,與稀疏嵌入相比較。
歡迎參考下列資源,進一步瞭解 Gemini:
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2025 年 7 月 10 日
實驗室上次測試日期:2025 年 6 月 13 日
Copyright 2025 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验