

准备工作
- 实验会创建一个 Google Cloud 项目和一些资源,供您使用限定的一段时间
- 实验有时间限制,并且没有暂停功能。如果您中途结束实验,则必须重新开始。
- 在屏幕左上角,点击开始实验即可开始
Install packages, and configure the notebook.
/ 15
Prepare the dataset
/ 15
Use token based search
/ 15
Create an index endpoint and sparse embedding index in Vector Search
/ 15
Create the hybrid index and deploy it to the Endpoint
/ 20
Run a hybrid query
/ 20
Vertex AI Vector Search 支持混合搜索。混合搜索是信息检索 (IR) 中常见的一种架构模式,可结合使用语义搜索和关键字搜索(也称为基于 token 的搜索)。借助混合搜索,开发者可以充分发挥这两种方法的优势,从而有效提升搜索质量。
在本实验中,您将学习如何使用混合搜索来搜索 Google 商品数据集中的内容。在本实验的最后,您将对混合搜索和基于 token 的搜索这两种方法的搜索结果进行比较。
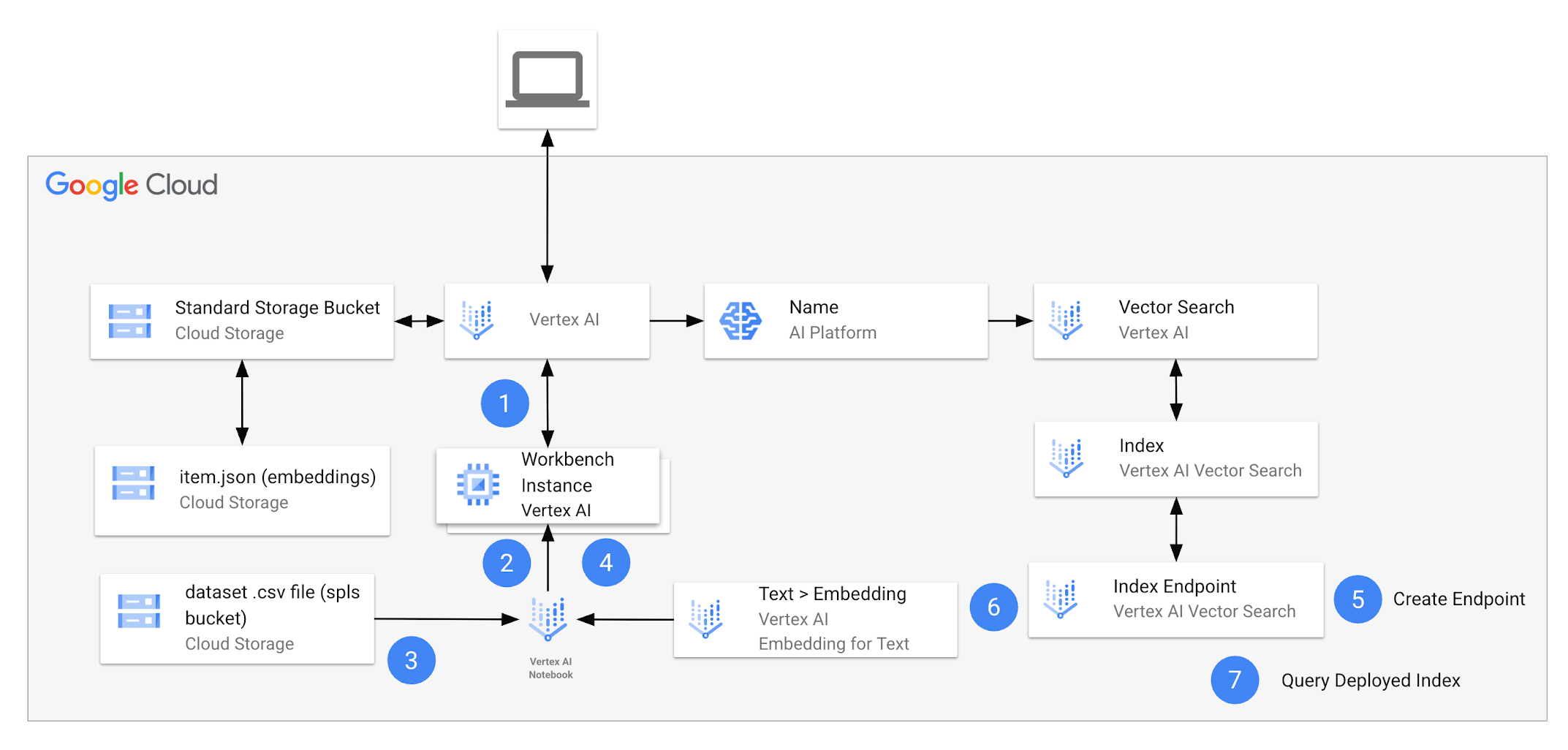
开始本实验时,实验环境中将包含下图所示的资源。
在实验结束时,您应该已使用该架构执行了多项任务。
下表详细说明了与该实验架构相关的每项任务。
| 任务编号 | 详细信息 |
|---|---|
| 1. | 在 Vertex AI Workbench 中打开笔记本并选择内核。 |
| 2. |
安装软件包,并为您的项目配置笔记本: 您将使用 Google Gen AI SDK,通过 Developer API 和 Vertex AI 处理文本嵌入模型。要完成此任务,您需要安装 Python 库,并在整个实验过程中引用这些 Python 库。您还需要配置笔记本,使其能够访问您项目中的资源,例如实验启动时提供给您的 Cloud Storage 存储桶。 |
| 3. |
准备数据集: 在此任务中,您将下载包含 Google Merch Shop 商品的 CSV 数据集文件,并将其添加到 Pandas DataFrame 中。 |
| 4. |
使用基于 token 的搜索: 您将训练向量化工具(一种根据文本生成稀疏嵌入的模型),然后将其应用于数据集。 |
| 5. |
创建索引端点: 在 Vertex AI Vector Search 中使用混合搜索之前,您必须先创建索引端点。 |
| 6. |
创建混合查询索引并将其部署到端点: 您将使用“text-embedding-005”模型为数据集内容生成密集嵌入,这些嵌入将结合稀疏嵌入来创建混合索引。此操作完成后,您需要将混合索引部署到您的端点中。 |
| 7. |
运行混合查询: 部署好索引后,您需要先创建 HybridQuery 对象来封装查询文本的稀疏嵌入,然后才能运行查询。 |
在开始本实验之前,您应该先熟悉:
在本实验中,您将执行以下操作:
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。为此,我们会向您提供新的临时凭据,您可以在该实验的规定时间内通过此凭据登录和访问 Google Cloud。
为完成此实验,您需要:
点击开始实验按钮。如果该实验需要付费,系统会打开一个对话框供您选择支付方式。左侧是“实验详细信息”窗格,其中包含以下各项:
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示“登录”页面。
提示:将这些标签页安排在不同的窗口中,并排显示。
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
您也可以在“实验详细信息”窗格中找到“用户名”。
点击下一步。
复制下面的密码,然后将其粘贴到欢迎对话框中。
您也可以在“实验详细信息”窗格中找到“密码”。
点击下一步。
继续在后续页面中点击以完成相应操作:
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

在 Google Cloud 控制台的导航菜单 (
找到
Workbench 实例的 JupyterLab 界面会在新浏览器标签页中打开。
1. 关闭 JupyterLab 的浏览器标签页,然后返回 Workbench 首页。
2. 选中实例名称旁边的复选框,然后点击重置。
3. 打开 JupyterLab 按钮重新启用后,请等待一分钟,然后点击打开 JupyterLab。
打开
在“选择内核”对话框中,从可用内核列表中选择 Python 3。
要开始使用笔记本,您首先要从第 1 部分“创建稀疏嵌入”开始。
在此任务中,您将安装所需的 Python 软件包、重启内核运行时、配置笔记本以便使用您的项目和区域,以及导入内容库。
完成任务 2“安装软件包并配置笔记本”中的单元。
对于项目 ID,请使用
点击检查我的进度以验证是否完成了以下目标:
在此任务中,您将下载 CSV 数据集文件,并准备好在笔记本中使用该文件。
点击检查我的进度以验证是否完成了以下目标:
在此任务中,您将创建稀疏嵌入,并在数据集中搜索“Chrome Dino Pin”商品,以获取其基于向量的值和维度。您还将检索数据集中其他商品的值。然后,您需要将这些数据保存到 Workbench 中的 items.json 文件中,并将此文件复制到您的 Cloud Storage 存储桶中。
点击检查我的进度以验证是否完成了以下目标:
现在,您将执行笔记本的第 2 部分,在该过程中,您将使用混合搜索。
首先,在此任务中,您将创建一个索引端点。
点击检查我的进度以验证是否完成了以下目标:
在此任务中,您将检索文本嵌入模型,针对某个商品运行示例查询以获取其密集嵌入,然后针对所有商品执行相同操作。随后,将这些内容存储在 items.json 文件中。最后,您将根据此文件创建混合索引,并将该索引部署到端点。
在等待混合索引部署期间,您可以前往 Vertex AI > Vector Search > 索引端点,查看其部署情况。
您还可以花点时间查看此演示。此演示提供了一个真实示例,可帮助您了解 Vector Search 的工作原理、探索语义搜索和混合搜索,并了解重排序的实际应用。您只需提交对动物、植物、电子商务商品或其他内容的简短描述,剩余步骤由 Vector Search 来完成!
点击检查我的进度以验证是否完成了以下目标:
在此任务中,您将使用刚刚部署好的混合索引运行混合查询,并将此查询的结果与稀疏嵌入进行比较。
点击检查我的进度以验证是否完成了以下目标:
在本实验中,您学习了如何在 Vertex AI Vector Search 中使用混合搜索,包括创建和部署混合搜索索引,以及查询该索引以与稀疏嵌入进行比较。
请参阅以下资源,详细了解 Gemini:
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
本手册的最后更新时间:2025 年 7 月 10 日
本实验的最后测试时间:2025 年 6 月 13 日
版权所有 2025 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。



此内容目前不可用
一旦可用,我们会通过电子邮件告知您

太好了!
一旦可用,我们会通过电子邮件告知您

一次一个实验
确认结束所有现有实验并开始此实验