

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Install packages, and configure the notebook.
/ 15
Prepare the dataset
/ 15
Use token based search
/ 15
Create an index endpoint and sparse embedding index in Vector Search
/ 15
Create the hybrid index and deploy it to the Endpoint
/ 20
Run a hybrid query
/ 20
Vertex AI Vector Search は、セマンティック検索とキーワード検索(トークンベース検索とも呼ばれます)の両方を組み合わせた情報検索(IR)の一般的なアーキテクチャ パターンであるハイブリッド検索をサポートしています。ハイブリッド検索を使用すると、2 つのアプローチの長所を活かして、検索の質を効果的に高めることができます。
このラボでは、Google の商品データセットを使用してハイブリッド検索を行う方法を学びます。ラボの最後では、ハイブリッド検索の結果とトークンベース検索の結果を比較します。
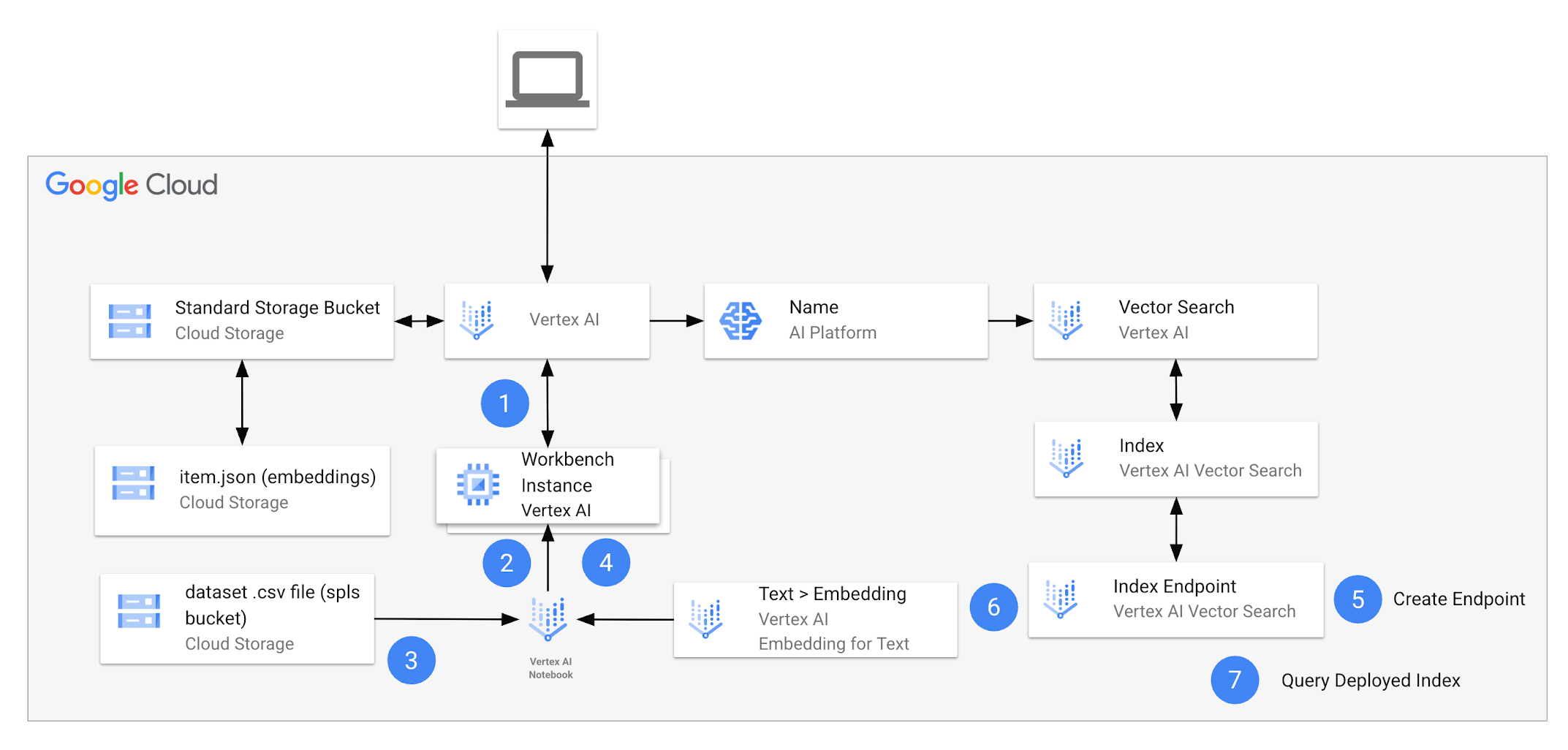
ラボを開始すると、次の図に示すリソースが含まれる環境が提供されます。
ラボを終えるまでに、このアーキテクチャを使用して複数のタスクを実行します。
次の表で、ラボのアーキテクチャに含まれる各タスクについて詳しく説明します。
| タスクの番号 | 詳細 |
|---|---|
| 1. | Vertex AI Workbench でノートブックを開き、カーネルを選択する。 |
| 2. |
パッケージをインストールし、プロジェクトのノートブックを構成する。 Google Gen AI SDK を使用し、Developer API と Vertex AI を介してテキスト エンベディング モデルを操作します。このためには、Python ライブラリをインストールし、ラボ全体で参照する必要があります。また、ラボの開始時に提供された Cloud Storage バケットなど、プロジェクト内のリソースにアクセスできるようにノートブックを構成する必要もあります。 |
| 3. |
データセットを準備する。 このタスクでは、Google Merchandise Store の商品を含むデータセットの .csv ファイルをダウンロードし、Pandas DataFrame に追加します。 |
| 4. |
トークンベース検索を使用する。 ベクトライザー(テキストから疎エンベディングを生成するモデル)をトレーニングしてから、データセットに適用します。 |
| 5. |
インデックス エンドポイントを作成する。 Vertex AI Vector Search でハイブリッド検索を使用するには、事前にインデックス エンドポイントを作成する必要があります。 |
| 6. |
ハイブリッド クエリ インデックスを作成してエンドポイントにデプロイする。 データセットの項目の密エンベディングを生成する「text-embedding-005」モデルを取得します。このモデルと疎エンベディングを組み合わて、ハイブリッド インデックスを作成します。これが完了したら、ハイブリッド インデックスをエンドポイントにデプロイします。 |
| 7. |
ハイブリッド クエリを実行する。 インデックスをデプロイしたら、まず HybridQuery オブジェクトを作成してクエリテキストの疎エンベディングをカプセル化する必要があります。その後、クエリを実行できます。 |
このラボを開始する前に、以下について理解しておく必要があります。
このラボでは、次の作業を行います。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Google Cloud コンソールのナビゲーション メニュー(
Workbench インスタンスの JupyterLab インターフェースが新しいブラウザタブで開きます。
1. JupyterLab のブラウザタブを閉じて、Workbench のホームページに戻ります。
2. インスタンス名の横にあるチェックボックスをオンにして、[リセット] をクリックします。
3. [JupyterLab を開く] ボタンが再度有効になったら、1 分待ってから [JupyterLab を開く] をクリックします。
[Select Kernel] ダイアログで、使用可能なカーネルのリストから [Python 3] を選択します。
ノートブックの使用を開始するには、セクション 1 の「Create sparse embeddings」(疎エンベディングを作成する)から始めます。
このタスクでは、必要な Python パッケージをインストールし、カーネル ランタイムを再起動します。続けて、目的のプロジェクトとリージョンを使用するようにノートブックを構成し、ライブラリをインポートします。
タスク 2 の「Install packages, and configure the notebook」(パッケージをインストールし、ノートブックを構成する)のセルを完了します。
[Project ID] には
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、データセットの .csv ファイルをダウンロードし、ノートブックで使用できるように準備します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、疎エンべディングを作成し、データセット内の項目「Chrome Dino Pin」を検索して、ベクトルベースの値と次元を取得します。また、データセット内の他の商品についてもこれらの値を取得します。次に、Workbench 内の items.json ファイルにこれらの値を保存し、このファイルを Cloud Storage バケットにコピーします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
次に、ハイブリッド検索を使用するノートブックのセクション 2 に進みます。
この 5 番目のタスクではまず、インデックス エンドポイントを作成します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、テキスト エンベディング モデルを取得し、1 つの項目の密エンベディングに対するサンプルクエリを実行してから、すべての項目に対してクエリを実行します。次に、これらを items.json ファイルに保存します。続けて、このファイルからハイブリッド インデックスを作成し、インデックスをエンドポイントにデプロイします。
ハイブリッド インデックスのデプロイを待っている間にその状況を確認するには、[Vertex AI] > [ベクトル検索] > [インデックス エンドポイント] に移動します。
また、こちらのデモもご覧ください。デモで紹介している現実に即した例で、ベクトル検索の仕組み、セマンティック検索とハイブリッド検索、再ランキングの流れを学ぶことができます。動物、植物、e コマースの商品、その他の項目の簡単な説明を送信すると、残りの手順は Vertex AI Vector Search が完了します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、先ほどデプロイしたハイブリッド インデックスを使用してハイブリッド クエリを実行し、このクエリの結果を疎エンベディングと比較します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このラボでは、Vertex AI Vector Search でハイブリッド検索を使用する方法を学びました。また、ハイブリッド検索インデックスを作成してデプロイする方法と、クエリを実行して疎エンベディングと比較する方法も学習しました。
以下のリソースで Gemini に関する理解を深めましょう。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 7 月 10 日
ラボの最終テスト日: 2025 年 6 月 13 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください