Informações gerais
Quanto melhores seus dados, melhor será a integração deles. Ao trabalhar com dados, é útil conferir como são os dados brutos para que seja possível usá-los como ponto de partida para a transformação. Com o Wrangler, você pode adotar uma abordagem com foco em dados para o fluxo de trabalho de integração de dados.
A fonte de dados mais comum para aplicativos ETL (extrair, transformar e carregar, em inglês) normalmente são dados armazenados em arquivos de texto no formato de valores separados por vírgula (CSV, na sigla em inglês), já que muitos sistemas de banco de dados exportam e importam dados dessa maneira. Para este laboratório, você usará um arquivo CSV, mas as mesmas técnicas podem ser aplicadas a fontes de banco de dados e a qualquer outra fonte de dados disponível no Cloud Data Fusion.
Objetivos
Neste laboratório, você aprenderá a fazer o seguinte:
- Criar um pipeline para fazer a ingestão de um arquivo CSV.
- Usar o Wrangler para aplicar transformações com interfaces rápidas e de linha de comando (CLI, na sigla em inglês).
Na maior parte deste laboratório, você trabalhará com as etapas de transformação do plug-in Wrangler, para que as transformações sejam encapsuladas em um só lugar e seja possível agrupar tarefas de transformação em blocos gerenciáveis. Essa abordagem com foco em dados permite visualizar rapidamente as transformações.
Configuração
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período sem custo financeiro.
-
Faça login no Google Cloud Ensina usando uma janela anônima.
-
Verifique o tempo de acesso do laboratório (por exemplo, 02:00:00) para conseguir finalizar todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas.
-
Quando tudo estiver pronto, clique em Começar o laboratório.
Observação: depois de clicar em Começar o laboratório, o tempo para provisionar os recursos necessários e criar uma instância do Data Fusion é de 15 a 20 minutos.
Enquanto isso, você pode conferir as etapas abaixo para conhecer as metas do laboratório.
Quando as credenciais do laboratório (nome de usuário e senha) aparecem no painel esquerdo, isso significa que a instância foi criada, e você pode continuar o login no console.
-
Anote as credenciais (nome de usuário e senha). É com elas que você vai fazer login no console do Google Cloud.
-
Clique em Abrir console do Google.
-
Clique em Usar outra conta e copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças.
-
Aceite os termos e pule a página de recursos de recuperação.
Observação: não clique em Terminar o laboratório a menos que você tenha concluído as atividades ou queira refazer tudo. Essa opção limpa as ações que você realizou e remove o projeto.
Fazer login no console do Google Cloud
- Na guia ou janela do navegador desta sessão de laboratório, copie o arquivo Nome de usuário do painel Detalhes da conexão e clique no botão Abrir console do Cloud.
Observação: se precisar escolher uma conta, clique em Usar outra conta.
- Cole o nome de usuário e a senha quando solicitado.
- Clique em Próxima.
- Aceite os Termos e Condições.
Como a conta é temporária, ela só dura até o final deste laboratório:
- não adicione opções de recuperação;
- não se inscreva em avaliações gratuitas.
- Assim que o console abrir, clique no menu de navegação (
 ) no canto superior esquerdo para acessar a lista de serviços.
) no canto superior esquerdo para acessar a lista de serviços.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
-
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell ( ).
).
-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:

Exemplo de comandos
gcloud auth list
(Saída)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemplo de saída)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Saída)
[core]
project = <project_ID>
(Exemplo de saída)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Verifique as permissões do projeto
Antes de começar a trabalhar no Google Cloud, confira se o projeto tem as permissões corretas no Identity and Access Management (IAM).
-
No Console do Google Cloud, acesse o menu de navegação () e clique em IAM e administrador > IAM.
-
Confira se a conta de serviço padrão do Compute {project-number}-compute@developer.gserviceaccount.com está na lista e recebeu o papel de editor. O prefixo da conta é o número do projeto, que pode ser encontrado em Menu de navegação > Visão geral do Cloud.

Se a conta não estiver no IAM ou não tiver o papel de editor, siga as etapas abaixo.
-
No Menu de navegação do console do Google Cloud, clique em Visão geral do Cloud.
-
No card Informações do projeto, copie o Número do projeto.
-
No Menu de navegação, clique em IAM e administrador > IAM.
-
Na parte superior da página IAM, clique em Adicionar.
-
Para Novos principais, digite:
{project-number}-compute@developer.gserviceaccount.com
Substitua {project-number} pelo número do seu projeto.
-
Em Selecionar um papel, selecione Básico (ou Projeto) > Editor.
-
Clique em Salvar.
Tarefa 1. Adicione as permissões necessárias para a instância do Cloud Data Fusion
-
Na barra de título do console do Google Cloud, no campo Pesquisar, digite Data Fusion, clique em Pesquisar e em Data Fusion.
-
Clique no ícone de fixação ao lado de Data Fusion.
Observação: a criação da instância demora entre 15 e 20 minutos. Aguarde até que ela fique pronta.
Em seguida, conceda permissões à conta de serviço associada à instância, de acordo com as etapas a seguir.
-
No console do Google Cloud, acesse IAM e administrador > IAM.
-
Confirme se a conta de serviço padrão do Compute Engine {project-number}-compute@developer.gserviceaccount.com está presente. Copie a conta de serviço para a área de transferência.
-
Na página de permissões do IAM, clique em +Conceder acesso.
-
No campo "Novos principais", cole a conta de serviço.
-
Clique no campo Selecionar um papel, comece a digitar "Agente de serviço da API Cloud Data Fusion" e selecione essa opção.
-
Clique em ADICIONAR OUTRO PAPEL.
-
Adicione o papel Administrador do Dataproc.
-
Clique em Salvar.
Clique em Verificar meu progresso para conferir o objetivo.
Adicionar um papel de agente de serviço da API Cloud Data Fusion à conta de serviço
Conceder permissão do usuário para a conta de serviço
-
No Console do Google Cloud, acesse IAM e administrador > IAM.
-
Marque a caixa de seleção ao lado de Incluir concessões do papel fornecidas pelo Google.

- Role a lista para baixo até encontrar a conta de serviço do Cloud Data Fusion gerenciada pelo Google que tem esta aparência
service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com e copie essa informação para a área de transferência.

-
Em seguida, acesse IAM e administrador > Contas de serviço.
-
Clique na conta padrão do Compute Engine que tem esta aparência: {project-number}-compute@developer.gserviceaccount.com. Depois disso, selecione a guia PERMISSÕES na parte de cima do menu de navegação.
-
Clique no botão CONCEDER ACESSO.
-
No campo Novos principais cole a conta de serviço que você copiou mais cedo.
-
No menu suspenso Papel, selecione Usuário da conta de serviço.
-
Clique em Salvar.
Tarefa 2. Carregue os dados
Em seguida, crie um bucket do Cloud Storage no projeto para carregar alguns dados de amostra para disponibilização. Depois, o Cloud Data Fusion lerá os dados desse bucket de armazenamento
- No Cloud Shell, execute os seguintes comandos para criar um novo bucket:
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
O nome do bucket criado é o ID do projeto.
- Execute o comando para copiar o arquivo de dados (um arquivo CSV) para o bucket:
gcloud storage cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Clique em Verificar meu progresso para conferir o objetivo.
Carregar os dados
Agora está tudo pronto para você prosseguir.
Tarefa 3. Navegue pela interface do Cloud Data Fusion
Na interface do Cloud Data Fusion, é possível usar as várias páginas, como o Pipeline Studio ou o Wrangler, para acessar os recursos dele.
Para navegar na interface do Cloud Data Fusion, siga estas etapas:
- No console, retorne para o Menu de navegação > Data Fusion.
- Clique no link Visualizar instância próximo da instância do Data Fusion.
- Selecione suas credenciais do laboratório para fazer login.
Observação: se você receber uma mensagem de erro 500, feche as guias e repita as etapas 2 e 3.
A interface da Web do Cloud Data Fusion tem o próprio painel de navegação à esquerda para navegar até a página necessária.
- Na interface do Cloud Data, clique no Menu de navegação no canto superior esquerdo para exibi-lo.
- Em seguida, selecione Wrangler.
Tarefa 4. Trabalhar com o Wrangler
O Wrangler é uma ferramenta visual e interativa que você pode usar para visualizar os efeitos das transformações em um pequeno subconjunto de dados, antes de aplicá-las a jobs grandes com processamento em paralelo no conjunto de dados inteiro.
-
Quando o Wrangler é carregado, no lado esquerdo aparece um painel com as conexões pré-configuradas para seus dados, incluindo a conexão do Cloud Storage.
-
No GCS, selecione Cloud Storage Default.
-
Clique no bucket que corresponde ao ID do seu projeto.
-
Clique em titanic.csv.
-
Nas opções de análise, selecione o formato de texto no menu suspenso.
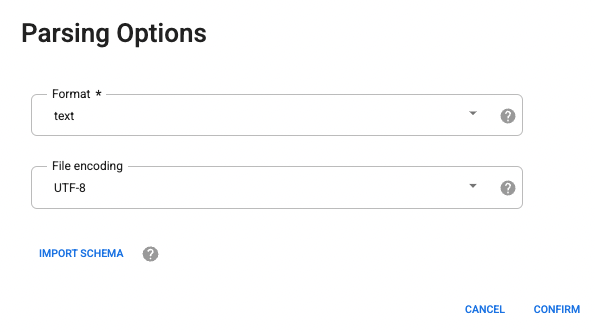
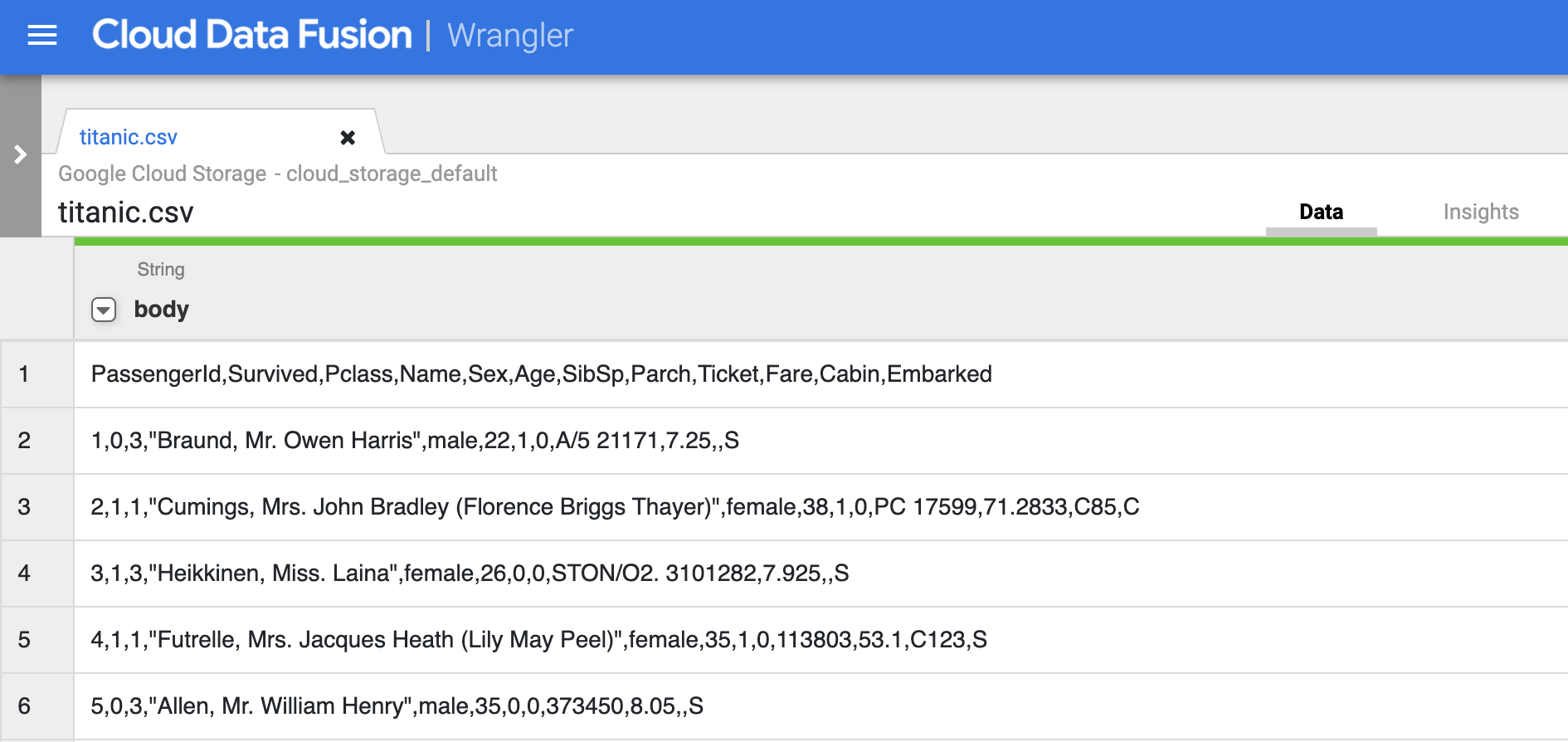
- Clique em Confirmar. Os dados são carregados no Wrangler.
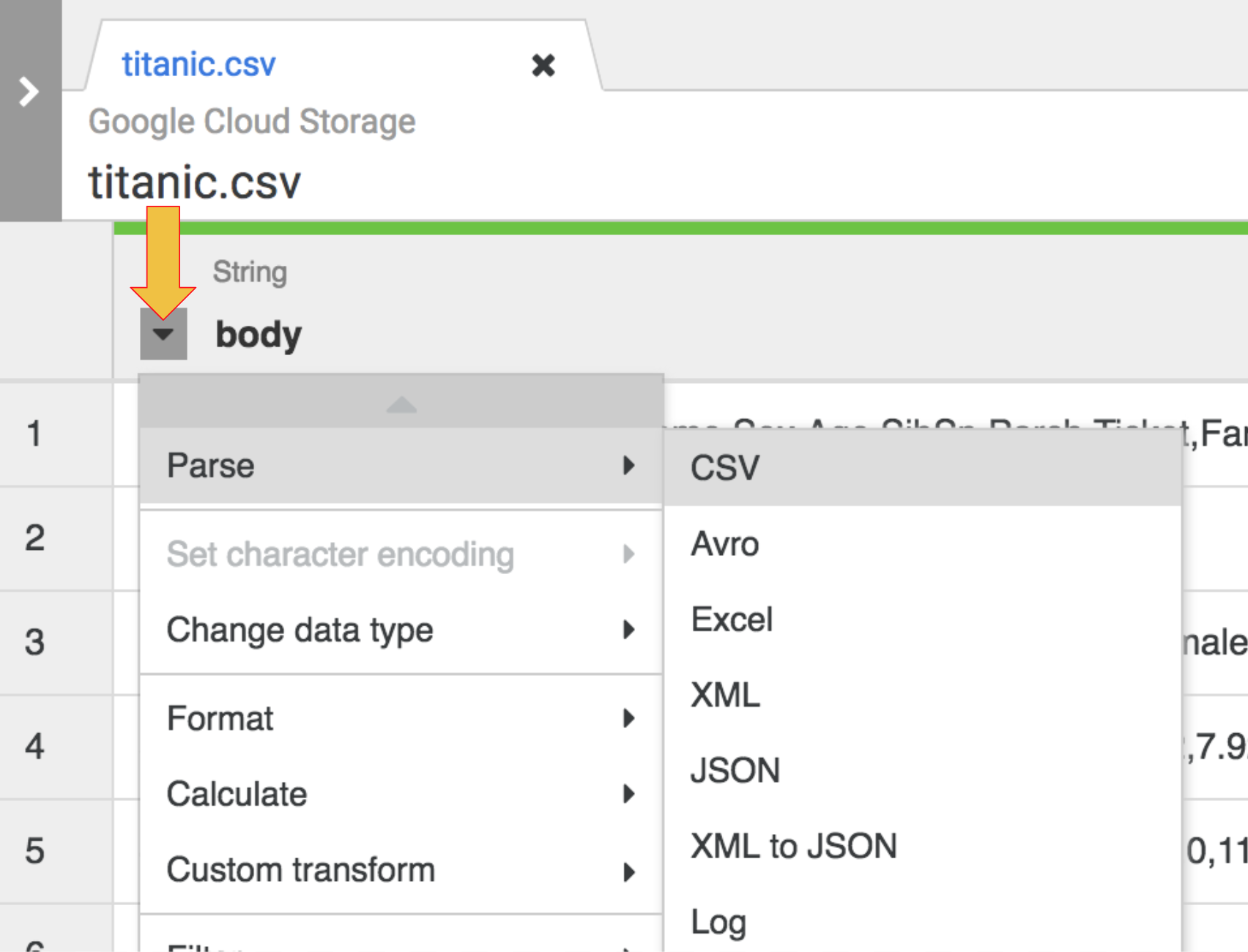
- A primeira operação é analisar os dados CSV brutos em uma representação tabular dividida em linhas e colunas. Para fazer isso, selecione o ícone do menu suspenso no cabeçalho da primeira coluna e, em seguida, selecione o item de menu Analisar e CSV no submenu.
-
Nos dados brutos, a primeira linha consiste em cabeçalhos de colunas. Selecione a opção Definir a primeira linha como cabeçalho na caixa de diálogo para Analisar como CSV que é exibida. Clique em Aplicar.
-
Nessa fase, os dados brutos são analisados. Confira as colunas geradas por essa operação à direita da coluna body.
-
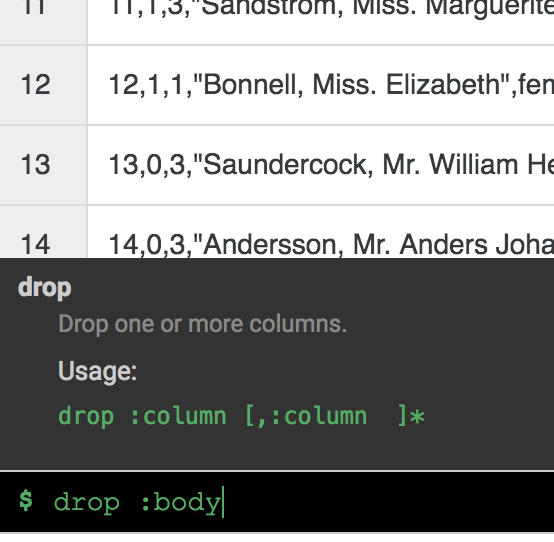
Você não precisa mais da coluna body. Para removê-la, selecione o ícone do menu suspenso próximo ao cabeçalho da coluna body e, em seguida, selecione o item de menu Excluir coluna.
Observação: para aplicar transformações, também é possível usar a interface de linha de comando (CLI, na sigla em inglês). A CLI é a barra preta da parte inferior da tela, com o indicador $ verde. Quando você começa a digitar comandos, o recurso de preenchimento automático é ativado e exibe uma opção correspondente. Por exemplo, para remover a coluna "body", você poderia ter usado a diretiva drop: body.
- Clique na guia Etapas de transformação na extremidade direita da interface do Wrangler. As duas transformações aplicadas até agora serão exibidas.
Observação: as seleções de menu e a CLI criam diretivas que ficam visíveis na guia Etapas de transformação à direita da tela. As diretivas são transformações individuais coletivamente chamadas de roteiro.
Mais adiante neste laboratório, você usará a CLI para adicionar mais etapas de transformação.
Ao aplicar as "Etapas de transformação" ao conjunto de dados, as transformações afetam os dados de amostra e fornecem dicas visuais que podem ser conferidas pelo navegador Insights.
- Clique na guia Insights na área central superior para analisar como os dados são distribuídos por várias colunas.
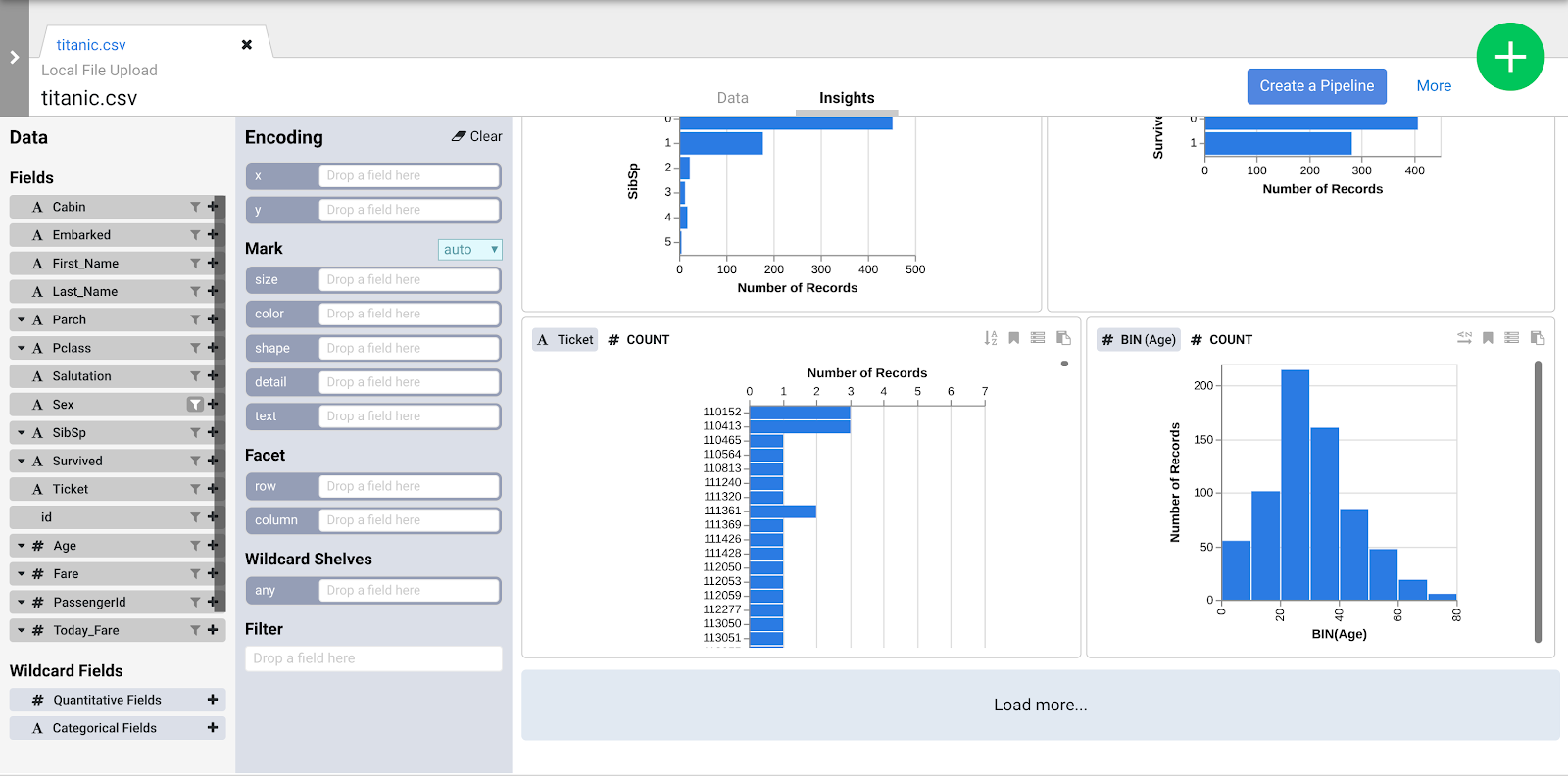
- Navegue pela interface para descobrir novas formas de analisar os dados. Arraste e solte o campo Idade para a codificação x para conferir como as perspectivas dos dados mudam.
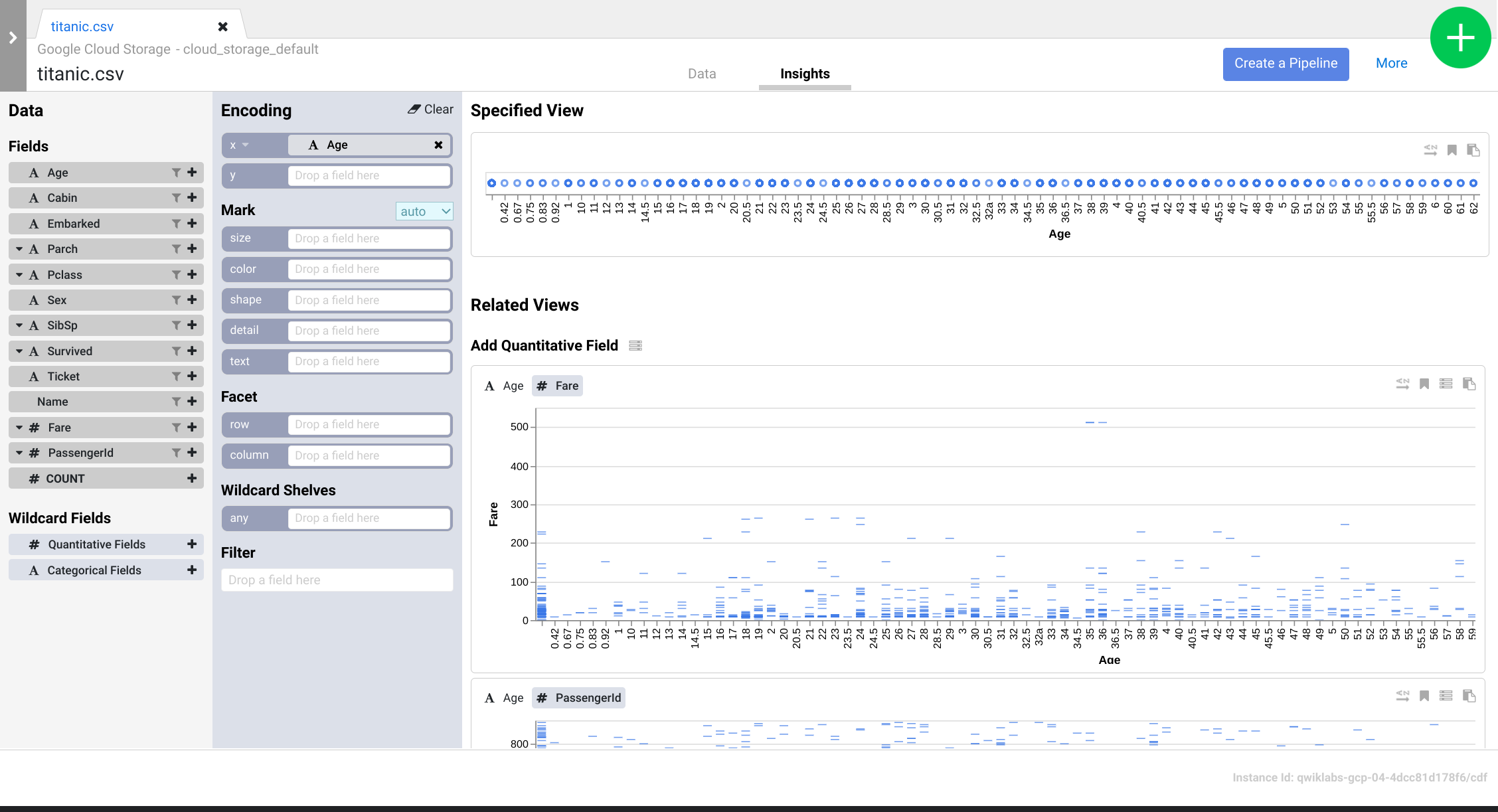
- Você pode clicar no botão Criar um pipeline para mudar para o modo de desenvolvimento de pipeline e verificar as diretivas criadas no plugin Wrangler.

- Quando a caixa de diálogo for exibida, selecione Pipeline em lote para continuar.
-
Quando o Pipeline Studio abrir, aponte para o nó do Wrangler e clique em Propriedades.
-
De acordo com as Diretivas, analise o roteiro de diretivas que você adicionou anteriormente. Na próxima seção, você usará a CLI para adicionar mais etapas de transformação.
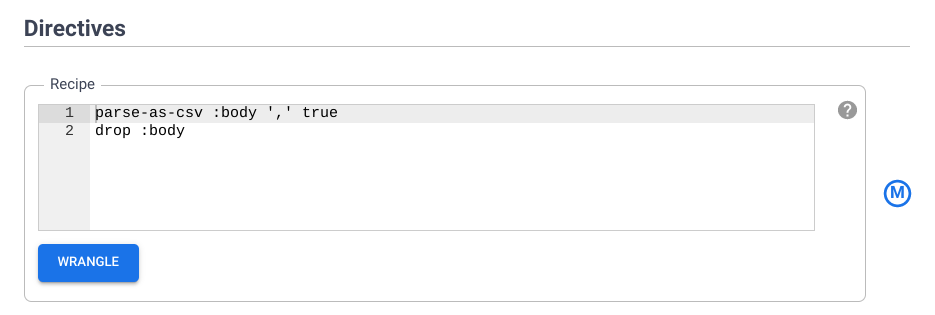
Tarefa 5. Trabalhar com etapas de transformação
Nesta seção, você continuará trabalhando na interface do Wrangler para analisar o conjunto de dados CSV e aplicar transformações pela CLI.
-
Clique no botão Wrangle na seção Diretivas da caixa Propriedades do nó do Wrangler. Você voltará à interface do Wrangler.
-
Clique nas Etapas de transformação na extremidade direita da interface do Wrangler para exibir as diretivas. Verifique se há duas etapas de transformação.
Adicione mais etapas de transformação usando a CLI e perceba como elas modificam os dados. A CLI é a barra preta da parte inferior da tela, com o comando $ verde.
- Copie as diretivas e cole-as na CLI do comando $. As Etapas de transformação exibidas à direita da tela serão atualizadas.
fill-null-or-empty :Cabin 'none'
send-to-error empty(Age)
parse-as-csv :Name ',' false
drop Name
fill-null-or-empty :Name_2 'none'
rename Name_1 Last_Name
rename Name_2 First_Name
set-type :PassengerId integer
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125)
set-type :Age integer
set-type :Fare double
set-column Today_Fare (Fare * 23.4058)+1
generate-uuid id
mask-shuffle First_Name
Confira a seguir uma explicação sobre o que as diretivas fazem com os dados. NÃO os insira novamente na CLI, porque você já fez isso.
a. fill-null-or-empty :Cabin 'none' corrige a coluna Cabine para que ela fique 100% completa.
b. send-to-error empty(Age) corrige a coluna Idade para que não haja células vazias.
c. parse-as-csv :Name ',' false divide as colunas Nome em duas colunas separadas com o nome e o sobrenome.
d. rename Name_1 Last_Name e rename Name_2 First_Name renomeiam as colunas recém-criadas, Name_1 e Name_2, como Last_Name e First_Name.
e. drop Name remove a coluna Nome porque ela não é mais necessária.
f. set-type :PassengerId integer converte a coluna PassengerId em um número inteiro.
g. As diretivas extraem a saudação da coluna "First_Name", excluem a coluna redundante e renomeiam as colunas recém-criadas de acordo:
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
h. A diretiva send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125) faz verificações de qualidade de dados na coluna Idade e set-type :Age integer a define como uma coluna com números inteiros.
i. set-type :Fare double converte a coluna Tarifa em "Dupla" para que você realize algumas operações aritméticas com os valores da coluna.
j. set-column Today_Fare (Fare * 23.4058)+1 multiplica a coluna Tarifa pela taxa de inflação do dólar desde 1912 para obter o valor ajustado do dólar.
k. generate-uuid id cria uma coluna de identidade para identificar exclusivamente cada registro.
l. mask-shuffle First_Name mascara a coluna Last_Name para desidentificar a pessoa, ou seja, PII.
-
Clique no link Mais no canto superior direito acima das Etapas de transformação, em seguida, clique em Exibir esquema, para examinar o esquema que as transformações geraram, e clique no ícone de download para fazer o download dele para o computador.
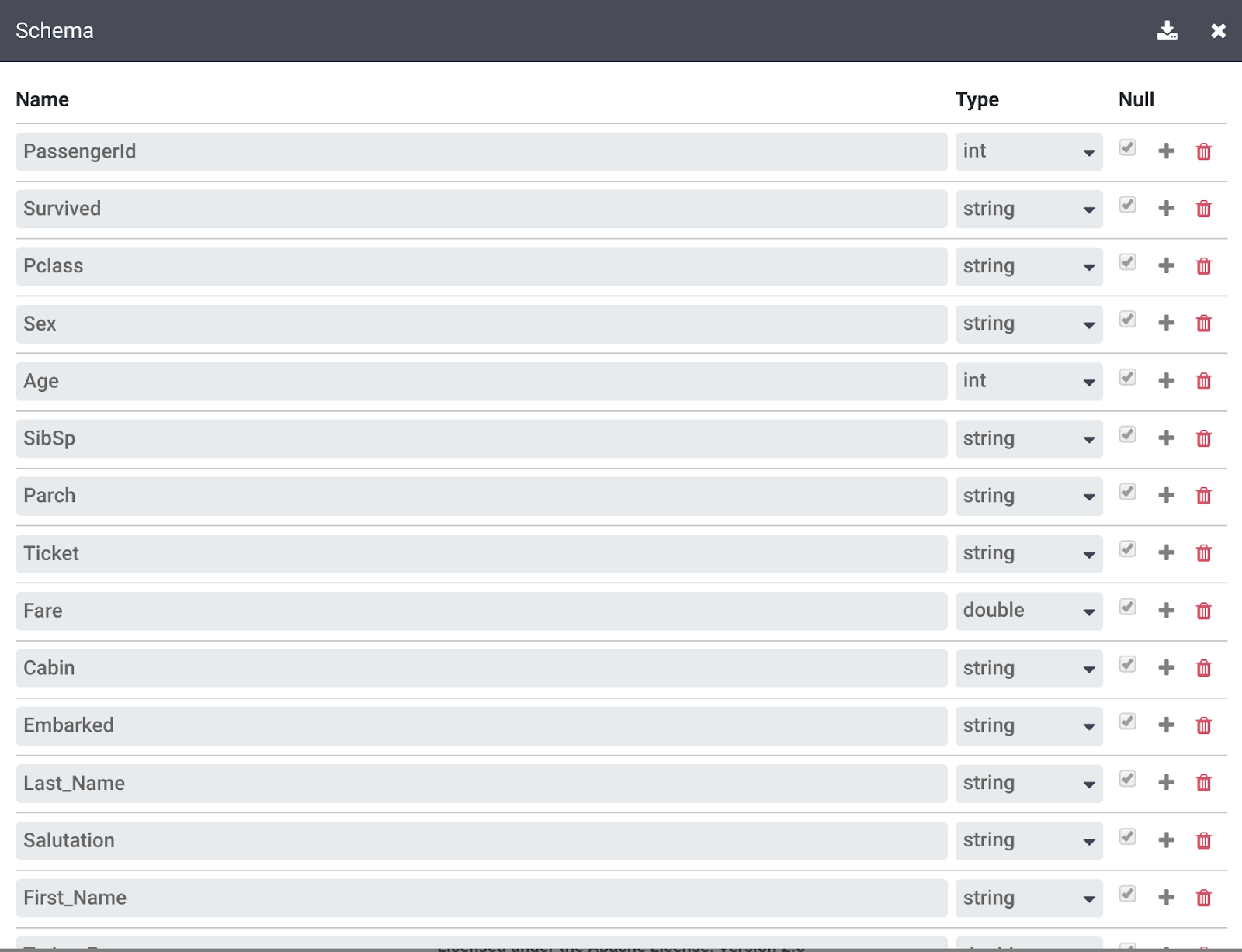
-
Clique no X para fechar a página "Esquema".
-
Você pode clicar no ícone de download em Etapas de transformação para fazer o download do roteiro das diretivas para o computador e manter uma cópia das etapas de transformação para uso futuro.

-
Clique no botão Aplicar no canto superior direito para que todas as etapas de transformação recém-inseridas sejam adicionadas à configuração do nó do Wrangler. Você voltará para a caixa de propriedades do nó do Wrangler.
-
Clique no X para fechar. Você está de volta ao Pipeline Studio.
Tarefa 6. Faça a ingestão no BigQuery
Para fazer a ingestão dos dados no BigQuery, crie um conjunto de dados.
-
Em uma nova guia, abra o BigQuery no console do Google Cloud ou clique com o botão direito do mouse na guia do console do Google Cloud, selecione Cópia e use o Menu de navegação para selecionar o BigQuery. Se for solicitado, clique em Concluído.
-
No painel "Explorar", clique no ícone Exibir ações próximo ao ID do projeto, que começa com qwiklabs, e selecione Criar conjunto de dados.
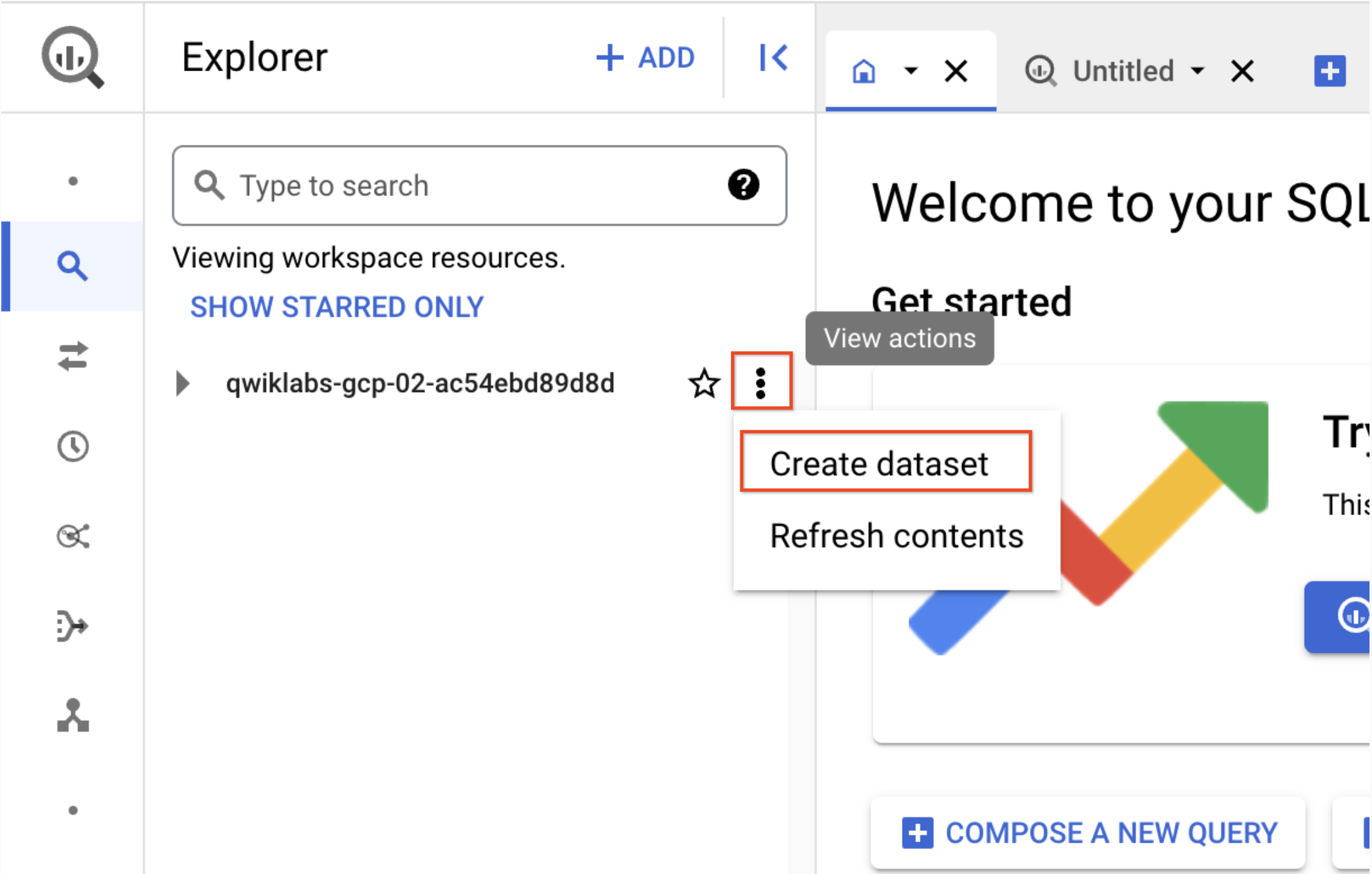
a. ID do conjunto de dados: demo_cdf
b. Clique em Criar conjunto de dados. Registre o nome para usar posteriormente no laboratório.
- Volte para a guia da interface do Cloud Data Fusion
a. Para adicionar o coletor do BigQuery ao pipeline, navegue até a seção Coletor no painel esquerdo e clique no ícone do BigQuery para colocá-lo na tela.
b. Depois que o coletor do BigQuery for colocado na tela, conecte o nó do Wrangler ao nó do BigQuery. Para isso, arraste a seta do nó do Wrangler para conectar-se ao nó do BigQuery, conforme ilustrado.
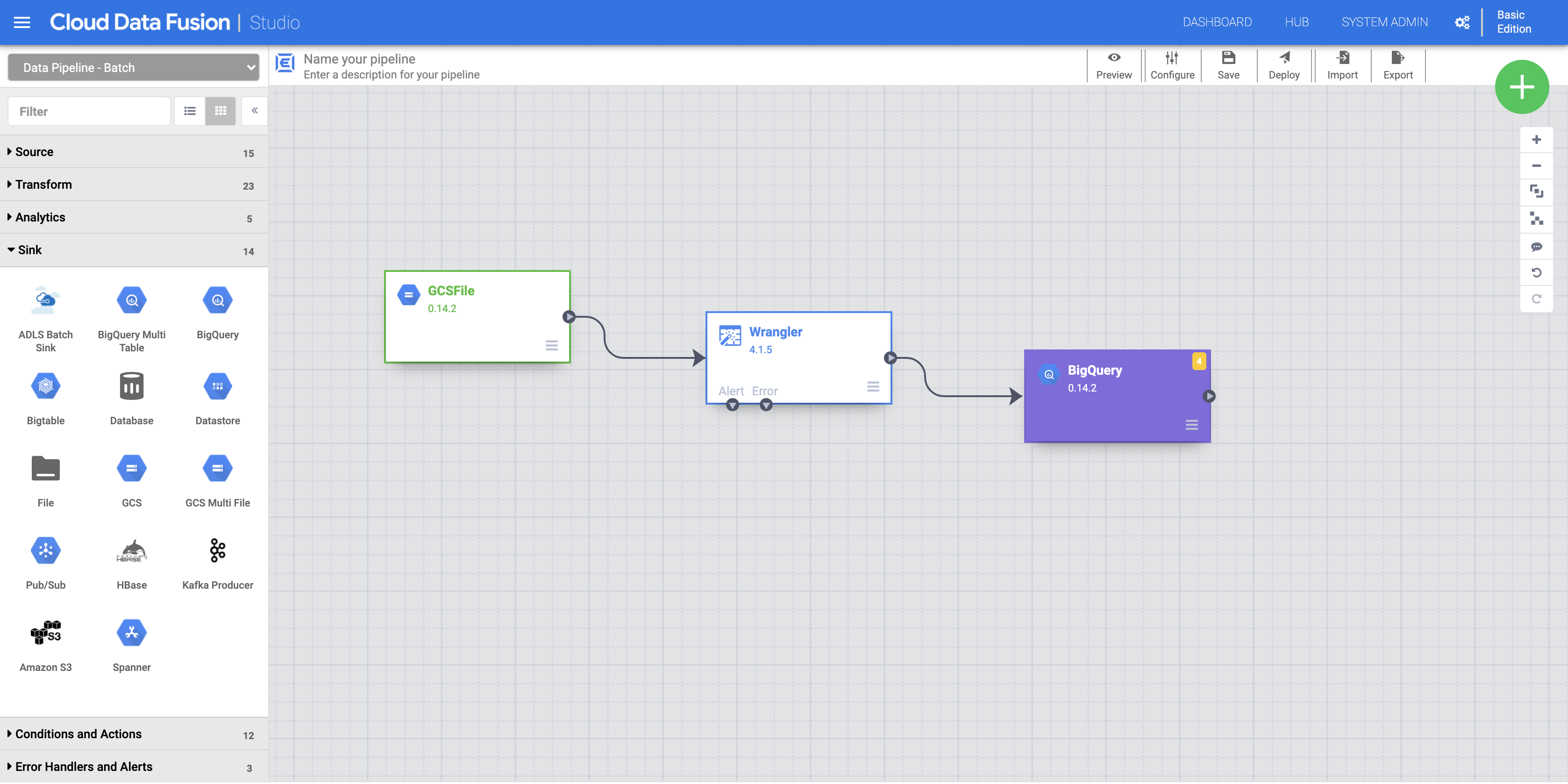
c. Aponte o mouse sobre o nó do BigQuery, clique em Propriedades e insira as seguintes configurações:
| Campo |
Valor |
| Nome de referência |
DemoSink |
| ID do projeto do conjunto de dados |
O ID do projeto
|
| Conjunto de dados |
demo_cdf (o conjunto de dados criado na etapa anterior) |
| Tabela |
Insira um nome apropriado (como titanic) |
A tabela será criada automaticamente.
d. Clique no botão Validar para verificar se tudo está configurado corretamente.
e. Clique no X para fechar. Você está de volta ao Pipeline Studio.
- Agora você pode executar o pipeline.
a. Dê um nome ao pipeline (como DemoBQ)
b. Clique em Salvar e em Implantar no canto superior direito para implantar o pipeline.
c. Clique em Executar para iniciar a execução do pipeline. Clique no ícone de Resumo para analisar algumas estatísticas.
Observação: se o pipeline falhar, execute-o novamente.
Quando a importação for concluída, o status muda para Concluído. Volte ao console do BigQuery para consultar os resultados.
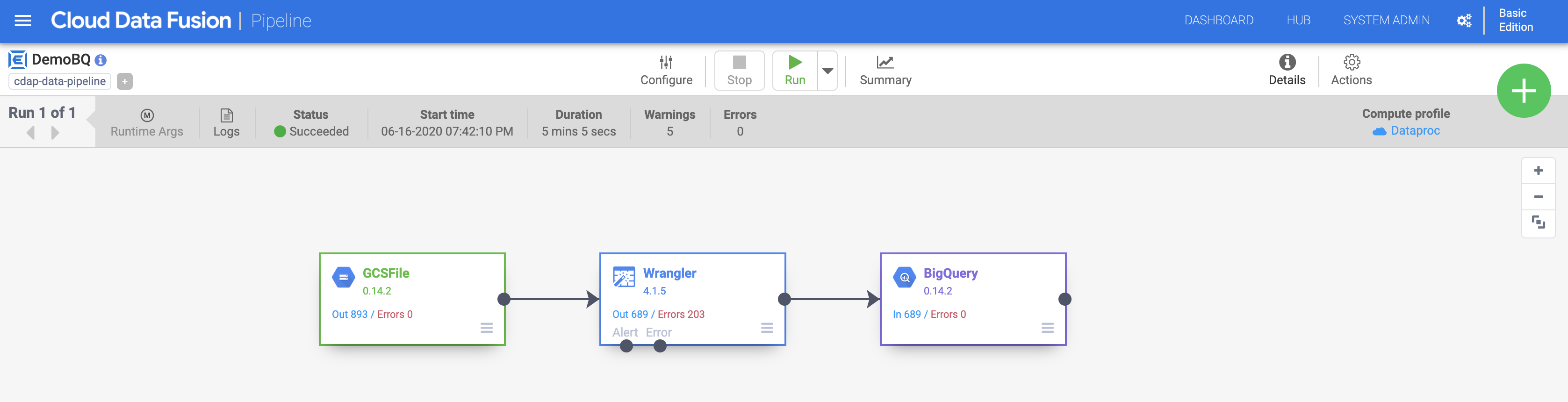
Clique em Verificar meu progresso para conferir o objetivo.
Fazer a ingestão no BigQuery
Parabéns!
Neste laboratório, você analisou a interface do Wrangler. Você aprendeu como adicionar etapas de transformação (diretivas) pelo menu e pela CLI. Com o Wrangler, é possível aplicar muitas transformações poderosas aos dados de forma iterativa. Você pode usar a interface do Wrangler para visualizar como isso afeta o esquema dos dados antes de implantar e executar o pipeline.
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
- 1 estrela = muito insatisfeito
- 2 estrelas = insatisfeito
- 3 estrelas = neutro
- 4 estrelas = satisfeito
- 5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Copyright 2020 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.





