Présentation
L'intégration des données repose entièrement sur vos données. Lorsque vous manipulez des données, il est utile de pouvoir voir à quoi ressemblent les données brutes afin de s'en servir comme point de départ pour votre transformation. Avec Wrangler, vous pouvez adopter une approche axée sur les données pour votre workflow d'intégration.
Les données stockées dans des fichiers texte au format CSV (valeurs séparées par une virgule) sont la source de données la plus courante pour les applications ETL (extraction, transformation et chargement), étant donné que de nombreux systèmes de base de données procèdent à l'importation et l'exportation des données via ce type de fichiers. Pour les besoins de cet atelier, vous utiliserez un fichier CSV, mais les mêmes techniques peuvent être appliquées aux sources de base de données et à toute autre source de données disponible dans Cloud Data Fusion.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Créer un pipeline pour l'ingestion de données à partir d'un fichier CSV
- Utiliser Wrangler pour appliquer des transformations en utilisant des interfaces de type pointer-cliquer et CLI
Pour la majeure partie de cet atelier, vous travaillerez avec les étapes de transformation Wrangler utilisées par le plugin Wrangler. Ainsi, vos transformations seront encapsulées en un seul endroit et vous pourrez regrouper les tâches de transformation en blocs faciles à gérer. Cette approche axée sur les données vous permettra de visualiser rapidement vos transformations.
Préparation
Pour chaque atelier, nous vous attribuons un nouveau projet Google Cloud et un nouvel ensemble de ressources pour une durée déterminée, sans frais.
-
Connectez-vous à Google Cloud Skills Boost dans une fenêtre de navigation privée.
-
Vérifiez le temps imparti pour l'atelier (par exemple : 02:00:00) : vous devez pouvoir le terminer dans ce délai.
Une fois l'atelier lancé, vous ne pouvez pas le mettre en pause. Si nécessaire, vous pourrez le redémarrer, mais vous devrez tout reprendre depuis le début.
-
Lorsque vous êtes prêt, cliquez sur Démarrer l'atelier.
Remarque : Une fois que vous avez cliqué sur Démarrer l'atelier, il faut compter environ 15-20 minutes pour que les ressources nécessaires soient provisionnées et une instance Data Fusion créée.
Pendant ce temps, vous pouvez parcourir les étapes ci-dessous pour vous familiariser avec les objectifs de l'atelier.
Les identifiants pour l'atelier (Username (Nom d'utilisateur) et Password (Mot de passe)) s'afficheront dans le volet de gauche une fois l'instance créée. Vous pourrez alors vous connecter à la console.
-
Notez ces identifiants (Username (Nom d'utilisateur) et Password (Mot de passe)). Ils vous serviront à vous connecter à la console Google Cloud.
-
Cliquez sur Open Google Console (Ouvrir la console Google).
-
Cliquez sur Utiliser un autre compte, puis copiez-collez les identifiants de cet atelier lorsque vous y êtes invité.
Si vous utilisez d'autres identifiants, des messages d'erreur s'afficheront ou des frais seront appliqués.
-
Acceptez les conditions d'utilisation et ignorez la page concernant les ressources de récupération des données.
Remarque : Ne cliquez pas sur Terminer l'atelier, à moins que vous n'ayez terminé l'atelier ou que vous ne vouliez le recommencer. Votre travail et le projet seront alors supprimés.
Se connecter à la console Google Cloud
- Dans l'onglet ou la fenêtre de navigateur que vous utilisez pour cet atelier, copiez les données de Username (Nom d'utilisateur) indiqué dans le panneau Connection Details (Détails de connexion), puis cliquez sur le bouton Open Google Console (Ouvrir la console Google).
Remarque : Si vous êtes invité à choisir un compte, cliquez sur Use another account (Utiliser un autre compte).
- Collez les données de Username (Nom d'utilisateur) et de Password (Mot de passe) lorsque vous y êtes invité :
- Cliquez sur Next (Suivant).
- Acceptez les conditions d'utilisation.
Comme il s'agit d'un compte temporaire auquel vous aurez accès uniquement pendant la durée de cet atelier :
- n'ajoutez pas d'options de récupération ;
- ne vous inscrivez pas à des essais gratuits.
- Une fois la console ouverte, affichez la liste des services en cliquant sur le menu de navigation (
 ) en haut à gauche.
) en haut à gauche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient des outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Google Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud. gcloud est l'outil de ligne de commande associé à Google Cloud. Il est préinstallé sur Cloud Shell et permet la saisie semi-automatique via la touche Tabulation.
-
Dans Google Cloud Console, dans le volet de navigation, cliquez sur Activer Cloud Shell ( ).
).
-
Cliquez sur Continuer.
Le provisionnement et la connexion à l'environnement prennent quelques instants. Une fois connecté, vous êtes en principe authentifié, et le projet est défini sur votre ID_PROJET. Exemple :

Exemples de commandes
gcloud auth list
(Résultat)
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
(Exemple de résultat)
Credentialed accounts:
- google1623327_student@qwiklabs.net
gcloud config list project
(Résultat)
[core]
project = <ID_Projet>
(Exemple de résultat)
[core]
project = qwiklabs-gcp-44776a13dea667a6
Vérifier les autorisations du projet
Avant de commencer à travailler dans Google Cloud, vous devez vous assurer de disposer des autorisations adéquates pour votre projet dans IAM (Identity and Access Management).
-
Dans la console Google Cloud, accédez au menu de navigation (), puis cliquez sur IAM et administration > IAM.
-
Vérifiez que le compte de service Compute par défaut {project-number}-compute@developer.gserviceaccount.com existe et qu'il est associé au rôle Éditeur. Le préfixe du compte correspond au numéro du projet, disponible sur cette page : Menu de navigation > Présentation Cloud.

Si le compte n'est pas disponible dans IAM ou n'est pas associé au rôle Éditeur, procédez comme suit pour lui attribuer le rôle approprié.
-
Dans la console Google Cloud, accédez au menu de navigation et cliquez sur Présentation Cloud.
-
Sur la carte Informations sur le projet, copiez le numéro du projet.
-
Dans le menu de navigation, cliquez sur IAM et administration > IAM.
-
En haut de la page IAM, cliquez sur Ajouter.
-
Dans le champ Nouveaux comptes principaux, saisissez :
{project-number}-compute@developer.gserviceaccount.com
Remplacez {project-number} par le numéro de votre projet.
-
Dans le champ Sélectionnez un rôle, sélectionnez De base (ou Projet) > Éditeur.
-
Cliquez sur Enregistrer.
Tâche 1 : Ajouter les autorisations nécessaires pour votre instance Cloud Data Fusion
-
Dans la barre de titre de la console Google Cloud, dans le champ Recherche, saisissez Data Fusion, cliquez sur Rechercher, puis sur Data Fusion.
-
Cliquez sur l'icône Épingler à côté de Data Fusion.
Remarque : La création de l'instance prend 15 à 20 minutes. Attendez qu'elle soit prête avant de continuer.
Vous allez ensuite accorder des autorisations au compte de service associé à l'instance en suivant les étapes ci-dessous.
-
Dans la console Google Cloud, accédez à IAM et Administration > IAM.
-
Vérifiez que le compte de service par défaut Compute Engine {project-number}-compute@developer.gserviceaccount.com est présent, puis copiez le Compte de service dans votre presse-papiers.
-
Sur la page des autorisations IAM, cliquez sur +Accorder l'accès.
-
Collez le compte de service dans le champ "Nouveaux comptes principaux".
-
Cliquez dans le champ Sélectionnez un rôle et commencez à saisir "Cloud Data Fusion API Service Agent" (agent de service de l'API Cloud Data Fusion), puis sélectionnez ce rôle lorsqu'il apparaît.
-
Cliquez sur AJOUTER UN AUTRE RÔLE.
-
Ajoutez le rôle Administrateur Dataproc.
-
Cliquez sur Enregistrer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ajouter le rôle Agent de service de l'API Cloud Data Fusion au compte de service
Accorder l'autorisation Utilisateur du compte de service
-
Dans la console, accédez à IAM et administration > IAM.
-
Cochez la case à côté de Inclure les attributions de rôles fournies par Google.

- Faites défiler la liste jusqu'au compte de service Cloud Data Fusion géré par Google, semblable à
service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.com. Copiez le nom dans votre presse-papiers.

-
Ensuite, accédez à IAM et administration > Comptes de service.
-
Cliquez sur le compte Compute Engine par défaut, semblable à {project-number}-compute@developer.gserviceaccount.com, et sélectionnez l'onglet AUTORISATIONS dans la barre de navigation supérieure.
-
Cliquez sur le bouton ACCORDER L'ACCÈS.
-
Dans le champ Nouveaux comptes principaux, collez le nom du compte de service que vous avez copié plus tôt.
-
Dans le menu déroulant Rôle, sélectionnez Utilisateur du compte de service.
-
Cliquez sur Enregistrer.
Tâche 2 : Charger les données
Vous allez maintenant créer un bucket Cloud Storage dans votre projet afin de pouvoir charger des échantillons de données pour Wrangling. Cloud Data Fusion lira par la suite les données dans ce bucket de stockage.
- Dans Cloud Shell, exécutez les commandes suivantes pour créer un bucket :
export BUCKET=$GOOGLE_CLOUD_PROJECT
gcloud storage buckets create gs://$BUCKET
Le nom du bucket créé correspond à l'ID de votre projet.
- Exécutez cette commande pour copier le fichier de données (un fichier CSV) dans votre bucket :
gcloud storage cp gs://cloud-training/OCBL163/titanic.csv gs://$BUCKET
Cliquez sur Vérifier ma progression pour valider l'objectif.
Charger les données
Vous êtes à présent prêt à poursuivre.
Tâche 3 : Parcourir l'UI de Cloud Data Fusion
Dans l'UI de Cloud Data Fusion, vous pouvez accéder à plusieurs pages, telles que Pipeline Studio ou encore Wrangler, qui permettent d'utiliser les différentes fonctionnalités de Cloud Data Fusion.
Pour ouvrir l'UI Cloud Data Fusion, procédez comme suit :
- Dans la console, revenez au menu de navigation > Data Fusion.
- Cliquez ensuite sur le lien Afficher l'instance à côté de votre instance Data Fusion.
- Pour vous connecter, utilisez les identifiants qui vous ont été attribués pour cet atelier.
Remarque : Si un message d'erreur 500 s'affiche, fermez vos onglets et réessayez d'effectuer les étapes 2 et 3.
L'UI Web de Cloud Data Fusion est dotée de son propre panneau de navigation (à gauche) qui permet d'accéder à la page souhaitée.
- Dans l'UI de Cloud Data Fusion, cliquez sur le menu de navigation situé en haut à gauche pour afficher le panneau de navigation.
- Choisissez ensuite Wrangler.
Tâche 4 : Utiliser Wrangler
Wrangler est un outil interactif, qui vous permet de visualiser les effets des transformations sur un petit sous-ensemble de vos données avant de répartir des jobs de traitement parallèle volumineux sur l'ensemble de données complet.
-
Au chargement de Wrangler, vous pouvez voir sur le côté gauche un panneau dans lequel figurent les connexions préconfigurées pour vos données, y compris la connexion Cloud Storage.
-
Sous GCS, sélectionnez l'option Cloud Storage Default (Cloud Storage par défaut).
-
Cliquez sur le bucket correspondant à l'ID de votre projet.
-
Cliquez sur titanic.csv.
-
Pour les options d'analyse, sélectionnez le format texte dans la liste déroulante.
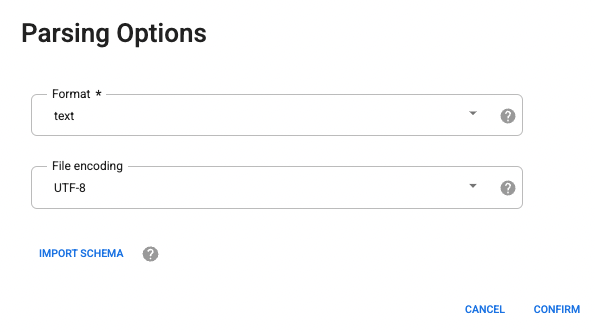
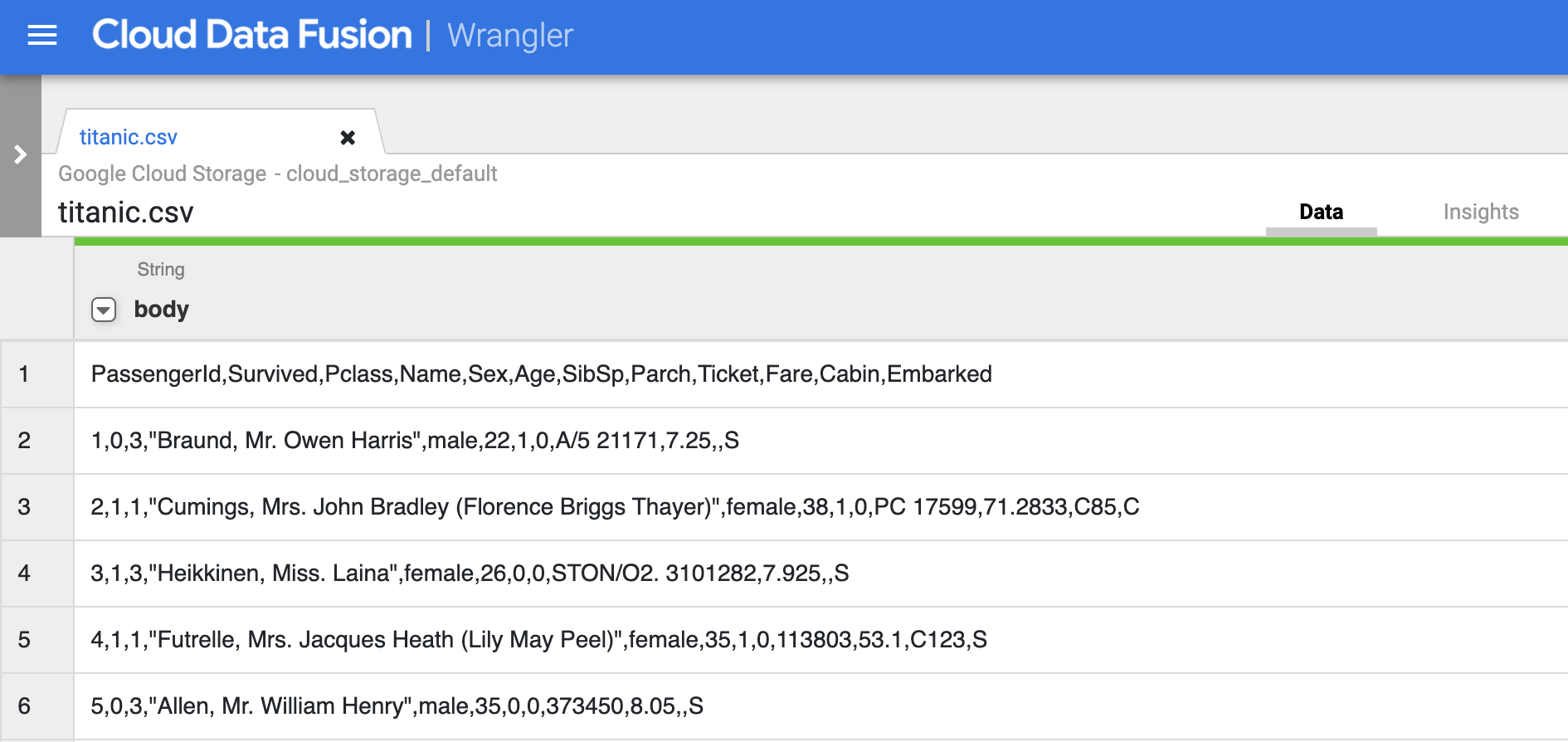
- Cliquez sur Confirm (Confirmer). Les données sont chargées dans Wrangler.
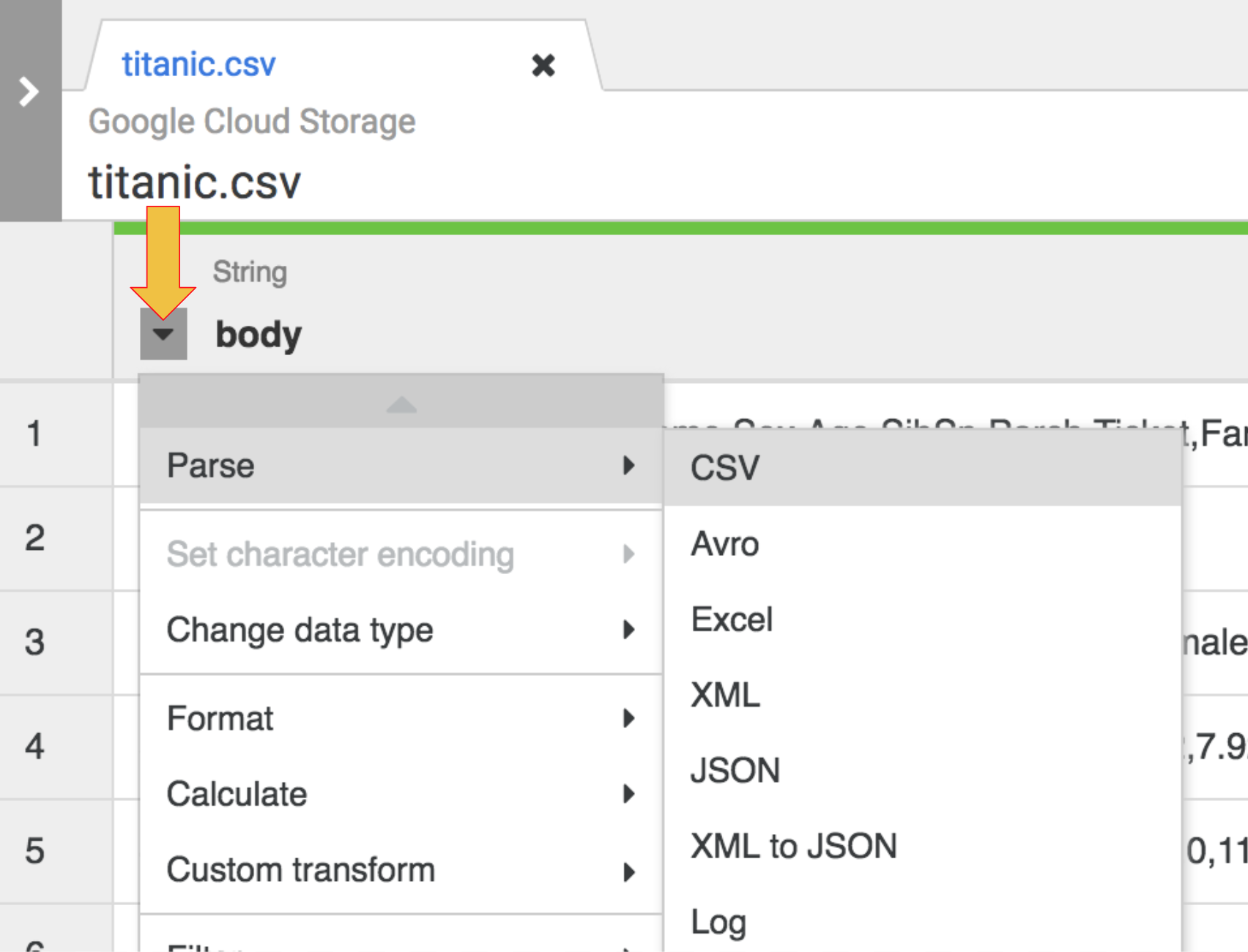
- La première opération consiste à analyser les données CSV brutes affichées sous la forme d'une représentation tabulaire divisée en lignes et en colonnes. Pour ce faire, vous devez sélectionner l'icône de menu déroulant située dans l'en-tête de la première colonne, puis l'élément de menu Parse (Analyser), et enfin CSV dans le sous-menu.
-
Dans les données brutes, nous pouvons voir que la première ligne est constituée d'en-têtes de colonnes. Vous devez donc sélectionner l'option Set first row as header (Définir la première ligne comme en-tête) dans la boîte de dialogue Parse as CSV (Analyser en tant que CSV) qui vous est présentée, puis cliquer sur Apply (Appliquer).
-
À ce stade, les données brutes sont analysées et vous pouvez voir les colonnes générées par cette opération à droite de la colonne body (corps).
-
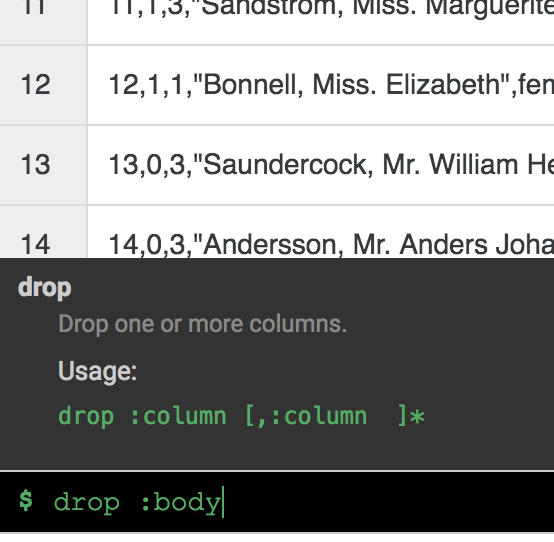
Vous n'avez plus besoin de la colonne body. Pour la supprimer, sélectionnez l'icône de menu déroulant située à côté de l'en-tête de la colonne body et choisissez l'option de menu Delete column (Supprimer la colonne).
Remarque : Pour appliquer des transformations, vous pouvez également utiliser l'interface de ligne de commande (CLI). La CLI est la barre noire située en bas de l'écran (avec l'invite de commande $ affichée en vert). Dès que vous commencez à saisir des commandes, la fonction de saisie semi-automatique s'active et vous présente une option correspondante. Par exemple, pour supprimer la colonne "corps", vous auriez pu utiliser la directive suivante : drop: body.
- Cliquez sur l'onglet Transformation steps (Étapes de transformation) situé tout à droite de l'UI Wrangler. Vous pouvez voir les deux transformations que vous avez appliquées jusqu'à présent.
Remarque :
Les sélections effectuées dans le menu et la CLI créent des directives qui sont visibles dans l'onglet Transformation steps (Étapes de transformation) situé à droite de l'écran. Les directives sont des transformations individuelles, qui sont collectivement désignées par le terme "recette".
Vous ajouterez d'autres étapes de transformation à l'aide de la CLI dans une prochaine partie de l'atelier.
Lorsque vous appliquez des étapes de transformation à votre ensemble de données, les transformations affectent les données échantillonnées et fournissent des repères visuels qui peuvent être examinés dans le navigateur Insights.
- Cliquez sur l'onglet Insights situé en haut au centre pour voir comment les données sont réparties dans les différentes colonnes.
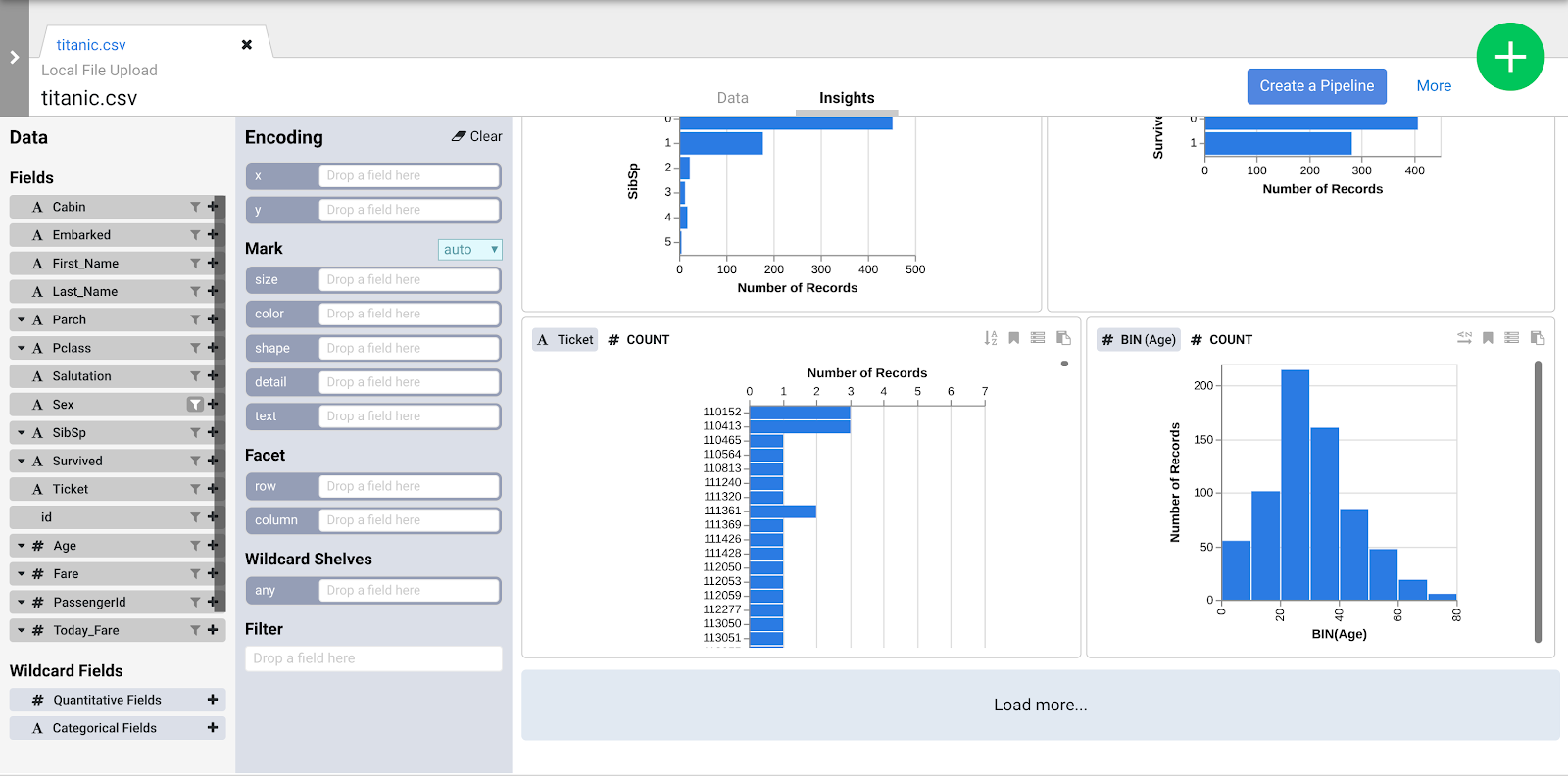
- Explorez l'interface pour découvrir de nouvelles façons d'analyser vos données. Glissez-déposez le champ Age (Âge) sur l'encodage x pour voir comment les perspectives de vos données changent.
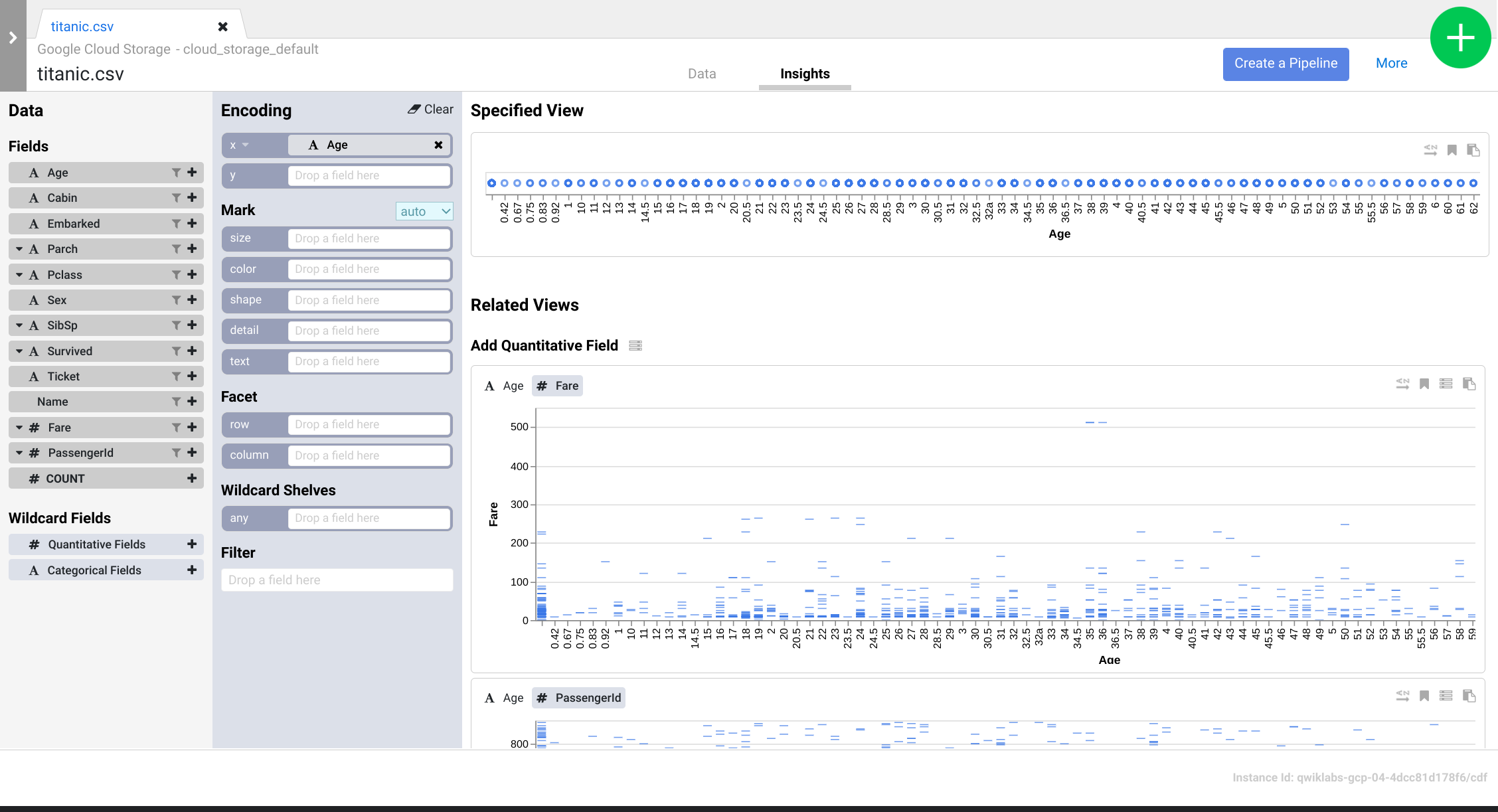
- Vous pouvez cliquer sur le bouton Create a Pipeline (Créer un pipeline) pour passer au mode de développement de pipeline. Ce mode vous permet de vérifier les directives que vous avez créées dans le plugin Wrangler.

- Lorsque la boîte de dialogue suivante s'affiche, sélectionnez Batch pipeline (Pipeline de traitement par lot) pour continuer.
-
Une fois que Pipeline Studio s'est ouvert, pointez votre curseur sur le noeud Wrangler et cliquez sur Properties (Propriétés).
-
Dans la section Directives, examinez la recette des directives que vous avez ajoutées précédemment. Vous ajouterez d'autres étapes de transformation à l'aide de la CLI dans la section suivante.
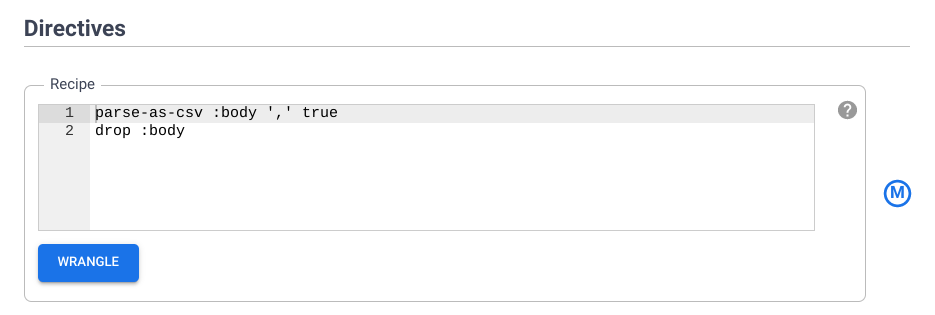
Tâche 5 : Utiliser les étapes de transformation
Dans cette section, vous allez continuer à travailler dans l'UI Wrangler pour explorer l'ensemble de données CSV et appliquer des transformations par l'intermédiaire de la CLI.
-
Dans la zone Properties (Propriétés) de votre nœud Wrangler, sous la section Directives, cliquez sur le bouton Wrangle. Ce bouton vous renvoie dans l'UI Wrangler.
-
Cliquez sur Transformation steps (Étapes de transformation) tout à droite de l'UI Wrangler pour afficher les directives. Vérifiez que vous avez actuellement deux étapes de transformation.
Vous allez maintenant ajouter d'autres étapes de transformation à l'aide de la CLI et voir comment elles modifient les données. La CLI est la barre noire située en bas de l'écran (avec l'invite de commande $ affichée en vert).
- Copiez les directives et collez-les dans la CLI au niveau de l'invite de commande $. Vous verrez les étapes de transformation à droite de votre écran se mettre à jour.
fill-null-or-empty :Cabin 'none'
send-to-error empty(Age)
parse-as-csv :Name ',' false
drop Name
fill-null-or-empty :Name_2 'none'
rename Name_1 Last_Name
rename Name_2 First_Name
set-type :PassengerId integer
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125)
set-type :Age integer
set-type :Fare double
set-column Today_Fare (Fare * 23.4058)+1
generate-uuid id
mask-shuffle First_Name
Voici une explication des effets de ces directives sur vos données. NE SAISISSEZ PAS à nouveau ces directives dans la CLI, vous l'avez déjà fait.
a. fill-null-or-empty :Cabin 'none' corrige la colonne Cabin pour qu'elle soit complète à 100 %.
b. send-to-error empty(Age) corrige la colonne Age de sorte qu'il n'y ait pas de cellules vides.
c. parse-as-csv :Name ',' false divise les colonnes Name en deux colonnes distinctes, l'une contenant le prénom et l'autre le nom de famille.
d. rename Name_1 Last_Name et rename Name_2 First_Name renomment les colonnes nouvellement créées, Name_1 et Name_2, en Last_Name et First_Name.
e. drop Name supprime la colonne Name, qui n'est plus nécessaire.
f. set-type :PassengerId integer convertit la colonne PassengerId en colonne de type "nombre entier".
g. Les directives extraient la formule de salutation de la colonne First_Name, suppriment la colonne redondante et renomment les colonnes nouvellement créées en conséquence :
parse-as-csv :First_Name '.' false
drop First_Name
drop First_Name_3
rename First_Name_1 Salutation
fill-null-or-empty :First_Name_2 'none'
rename First_Name_2 First_Name
h. La directive send-to-error !dq:isNumber(Age) || !dq:isInteger(Age) || (Age == 0 || Age > 125) effectue des contrôles de qualité des données sur la colonne Age, tandis que set-type :Age integer la définit comme une colonne d'entiers.
i. set-type :Fare double convertit la colonne Fare en un Double (la duplique) pour que vous puissiez effectuer des opérations arithmétiques avec les valeurs de la colonne.
j. set-column Today_Fare (Fare * 23.4058)+1 multiplie les valeurs de la colonne Fare par le taux d'inflation du dollar depuis 1912 pour obtenir des valeurs en dollar constant.
k. generate-uuid id crée une colonne d'identité pour identifier de manière unique chaque enregistrement.
l. mask-shuffle First_Name va masquer la colonne Last_Name pour anonymiser la personne, c'est-à-dire masquer les informations permettant d'identifier personnellement l'utilisateur.
-
Cliquez sur le lien More (Plus) situé en haut à droite au-dessus de vos étapes de transformation, puis sur View Schema (Afficher le schéma) pour examiner le schéma généré par les transformations, et enfin cliquez sur l'icône de téléchargement pour télécharger le schéma sur votre ordinateur.
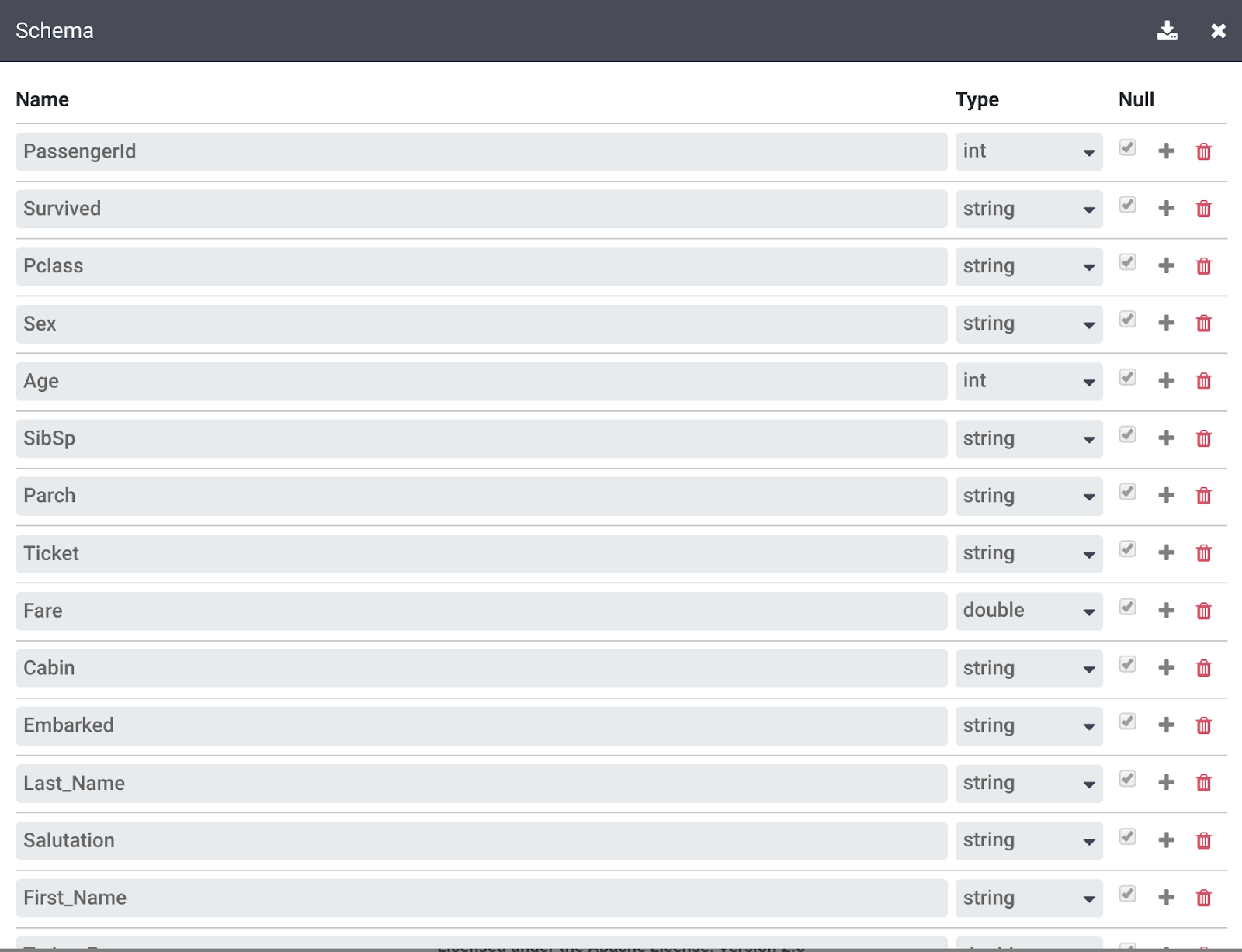
-
Cliquez sur X pour fermer la page du schéma.
-
Vous pouvez cliquer sur l'icône de téléchargement située sous les étapes de transformation pour télécharger la recette des directives sur votre ordinateur et ainsi conserver une copie des étapes de transformation pour un usage ultérieur.

-
Cliquez sur le bouton Apply (Appliquer) situé en haut à droite pour vous assurer que toutes les étapes de transformation nouvellement saisies ont bien été ajoutées à la configuration du nœud Wrangler. Vous êtes ensuite redirigé vers la zone des propriétés du nœud Wrangler.
-
Cliquez sur X pour quitter. Vous êtes de retour dans Pipeline Studio.
Tâche 6 : Ingestion dans BigQuery
Afin d'ingérer les données dans BigQuery, vous devez créer un ensemble de données.
-
Dans un nouvel onglet, ouvrez BigQuery dans la console Google Cloud. Vous pouvez également faire un clic droit sur l'onglet de la console Google Cloud et sélectionner Dupliquer, puis utiliser le menu de navigation du nouvel onglet pour sélectionner BigQuery. Si vous y êtes invité, cliquez sur OK.
-
Dans le volet "Explorateur", cliquez sur l'icône Afficher les actions située à côté de l'ID de votre projet (celui-ci commence par qwiklabs), puis sélectionnez Créer un ensemble de données.
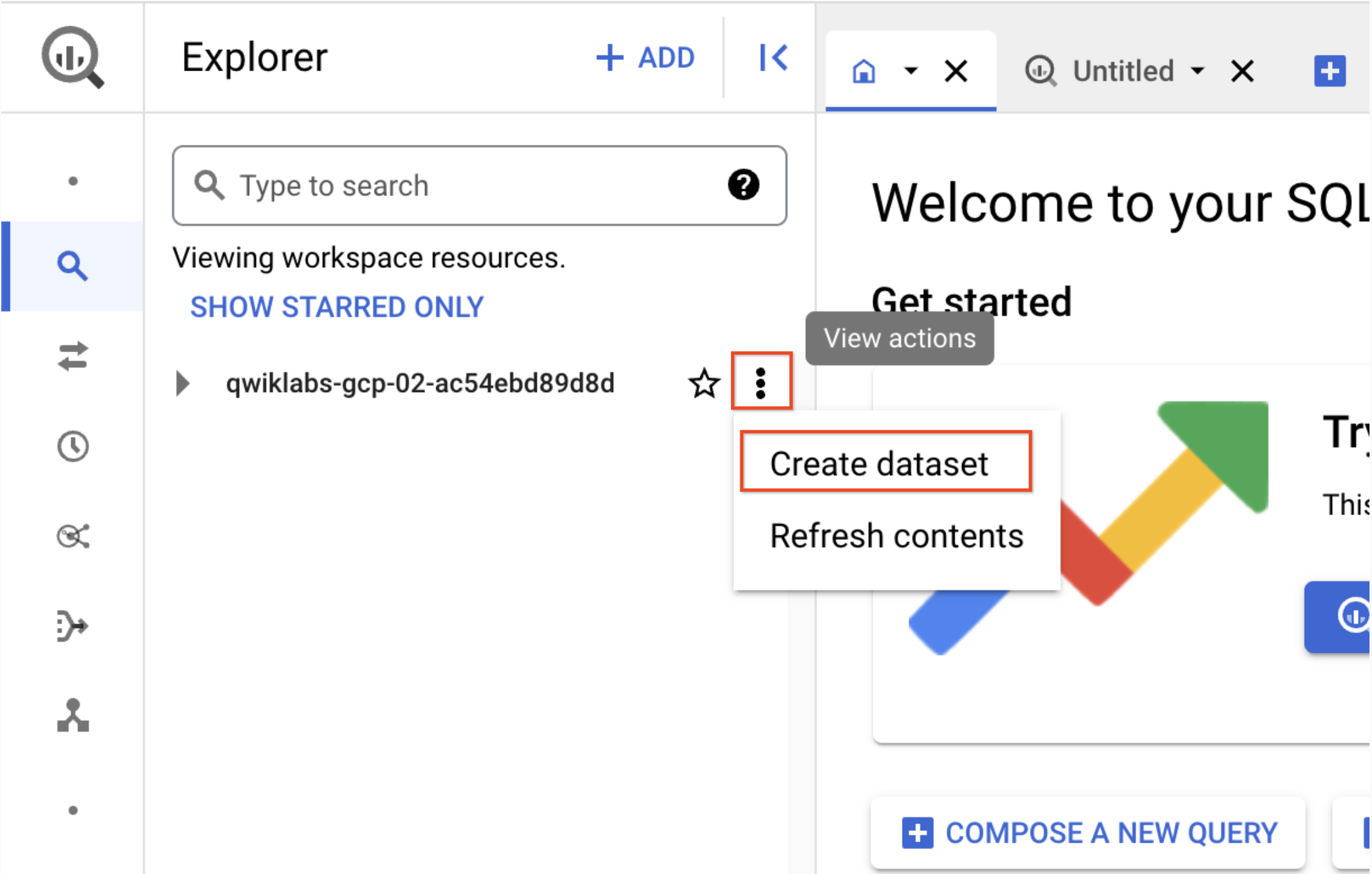
a. ID de l'ensemble de données : demo_cdf
b. Cliquez sur Créer un ensemble de données. Notez le nom de l'ensemble de données. Vous l'utiliserez plus tard dans l'atelier.
- Retournez sur l'onglet de l'UI de Cloud Data Fusion.
a. Pour ajouter le récepteur BigQuery au pipeline, accédez à la section Sink (Récepteur) du panneau de gauche et cliquez sur l'icône BigQuery afin de placer le récepteur sur le canevas.
b. Une fois le récepteur BigQuery placé sur le canevas, connectez le nœud Wrangler au nœud BigQuery. Pour ce faire, faites glisser la flèche en partant du nœud Wrangler vers le nœud BigQuery, comme illustré.
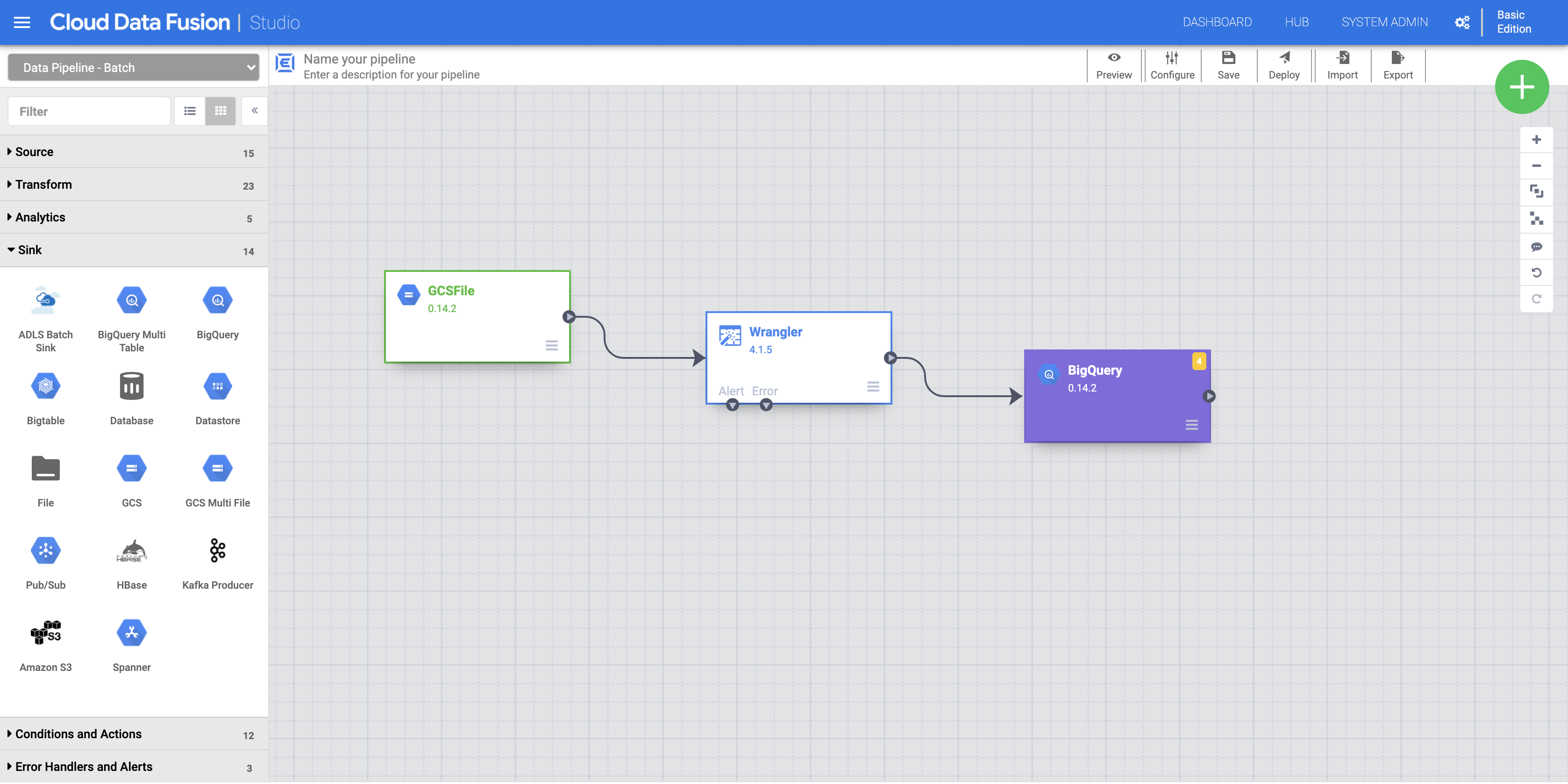
c. Pointez votre souris sur votre nœud BigQuery, cliquez sur Properties (Propriétés) et entrez les paramètres de configuration suivants :
| Champ |
Valeur |
|
Reference Name (Nom de référence) |
DemoSink |
|
Dataset Project ID (ID du projet de l'ensemble de données) |
ID de votre projet |
|
Dataset (Ensemble de données) |
demo_cdf (l'ensemble de données que vous avez créé à l'étape précédente) |
| Table |
Saisissez un nom approprié (par exemple titanic) |
La table sera créée automatiquement.
d. Cliquez sur le bouton Validate (Valider) pour vérifier si tout est correctement configuré.
e. Cliquez sur X pour quitter. Vous êtes de retour dans Pipeline Studio.
- Vous pouvez à présent exécuter votre pipeline.
a. Attribuez un nom à votre pipeline (par exemple DemoBQ)
b. Cliquez sur Save, (Enregistrer) puis sur Deploy (Déployer) en haut à droite pour déployer le pipeline.
c. Cliquez sur Run (Exécuter) pour lancer l'exécution du pipeline. Vous pouvez cliquer sur l'icône Summary (Résumé) pour afficher certaines statistiques.
Remarque : Si le pipeline échoue, veuillez l'exécuter à nouveau.
Une fois l'exécution terminée, l'état de l'opération passe à Succeeded (Réussie). Retournez dans la console BigQuery pour interroger les résultats.
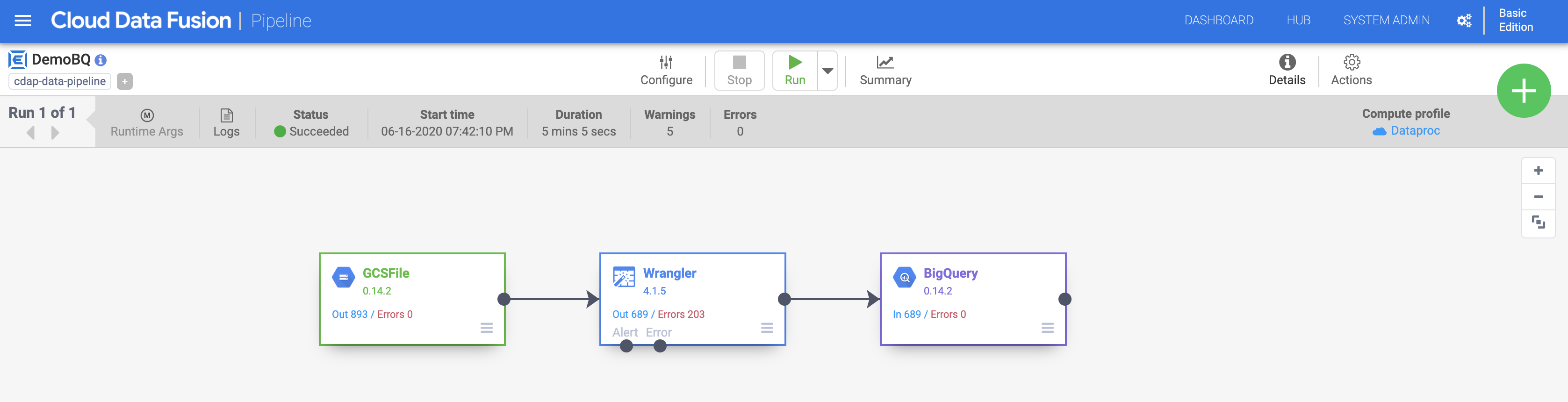
Cliquez sur Vérifier ma progression pour valider l'objectif.
Ingestion dans BigQuery
Félicitations !
Cet atelier vous a permis d'explorer l'UI Wrangler. Vous savez désormais comment ajouter des étapes de transformation (directives) via le menu et la CLI. Wrangler vous permet d'appliquer de nombreuses transformations puissantes à vos données, et ce de manière itérative. L'UI Wrangler vous permet également de voir et comprendre comment ces transformations affectent le schéma de vos données avant de passer au déploiement et à l'exécution de votre pipeline.
Terminer l'atelier
Une fois l'atelier terminé, cliquez sur End Lab (Terminer l'atelier). Qwiklabs supprime les ressources que vous avez utilisées, puis efface le compte.
Si vous le souhaitez, vous pouvez noter l'atelier. Sélectionnez le nombre d'étoiles correspondant à votre note, saisissez un commentaire, puis cliquez sur Submit (Envoyer).
Le nombre d'étoiles que vous pouvez attribuer à un atelier correspond à votre degré de satisfaction :
- 1 étoile = très mécontent(e)
- 2 étoiles = insatisfait(e)
- 3 étoiles = ni insatisfait(e), ni satisfait(e)
- 4 étoiles = satisfait(e)
- 5 étoiles = très satisfait(e)
Si vous ne souhaitez pas donner votre avis, vous pouvez fermer la boîte de dialogue.
Pour soumettre des commentaires, suggestions ou corrections, veuillez utiliser l'onglet Support (Assistance).
Copyright 2020 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





