Data Catalog は非推奨となり、2026 年 1 月 30 日に廃止されます。このラボは、引き続き必要に応じて実行することができます。
Data Catalog のユーザー、ワークロード、コンテンツを Dataplex Catalog に移行する手順については、「Data Catalog から Dataplex Catalog への移行」(https://cloud.google.com/dataplex/docs/transition-to-dataplex-catalog)をご覧ください。
GSP814

概要
Dataplex は、データレイク、データ ウェアハウス、データマートに分散したデータの一元的な検出、管理、モニタリング、統制を実現し、大規模な分析を支援するインテリジェントなデータ ファブリックです。
Data Catalog は、Dataplex 内のスケーラブルなフルマネージド型メタデータ管理サービスです。データ検出のためのシンプルで使いやすい検索インターフェースと、テクニカル メタデータおよびビジネス メタデータの両方を取得できる柔軟で強力なカタログ化システムを提供しています。また、Cloud Data Loss Prevention(Sensitive Data Protection の一部)および Identity and Access Management(IAM)とのインテグレーションにより、セキュリティとコンプライアンスの強固な基盤を備えています。
Data Catalog の使用
Dataplex 内の Data Catalog を使用すると、アクセス可能なアセットを検索して、データアセットにタグを付けて検出とアクセス制御をサポートできます。タグによって特定のデータアセットにカスタム メタデータ フィールドを追加できるため(例: 保護対象データや機密データを含む特定のアセットにタグを付ける)、簡単にアセットを識別して取得できるようになります。また、再利用可能なタグ テンプレートを作成すると、同じタグを別のデータアセットに迅速に割り当てることができます。
学習内容
このラボでは、次の方法について学びます。
- Data Catalog API を有効にする
- PostgreSQL と MySQL 用の Dataplex コネクタを構成する
- Dataplex 内の Data Catalog で PostgreSQL と MySQL のエントリを検索する
前提条件
注: ラボを開始する前に個人または企業の Gmail アカウントからログアウトするか、このラボをシークレット モードで実行してください。これにより、ラボの受講中にログインによる混乱を避けることができます。
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モード(推奨)またはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生しないようにすることができます。
- ラボを完了するための時間(開始後は一時停止できません)
注: このラボでは、受講者アカウントのみを使用してください。別の Google Cloud アカウントを使用すると、そのアカウントに料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。
左側の [ラボの詳細] ペインには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。
-
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの詳細] ペインでもユーザー名を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの詳細] ペインでもパスワードを確認できます。
-
[次へ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
-
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスにアクセスするには、ナビゲーション メニューをクリックするか、[検索] フィールドにサービス名またはプロダクト名を入力します。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
-
Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン  をクリックします。
をクリックします。
-
ウィンドウで次の操作を行います。
- Cloud Shell 情報ウィンドウで操作を進めます。
- Cloud Shell が認証情報を使用して Google Cloud API を呼び出すことを承認します。
接続した時点で認証が完了しており、プロジェクトに各自の Project_ID、 が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
- [承認] をクリックします。
出力:
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
注: Google Cloud における gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. Data Catalog API を有効にする
-
Google Cloud コンソールで、ナビゲーション メニュー( )> [API とサービス] > [ライブラリ] をクリックします。
)> [API とサービス] > [ライブラリ] をクリックします。
-
検索バーに「Data Catalog」と入力し、[Google Cloud Data Catalog API] を選択します。
-
[有効にする] をクリックします。
注: Data Catalog API の有効化を試した後に「操作の失敗」を示すエラーが発生した場合は、[閉じる] をクリックしてブラウザタブを更新してから、[有効にする] をもう一度クリックしてください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Data Catalog API を有効にする
タスク 2. PostgreSQL から Dataplex
プロジェクト ID の変数を作成する
- Cloud Shell で次のコマンドを実行して、プロジェクト ID を環境変数として設定します。
export PROJECT_ID=$(gcloud config get-value project)
PostgreSQL データベースを作成する
- 次のコマンドを実行して、GitHub リポジトリのクローンを作成します。
gsutil cp gs://spls/gsp814/cloudsql-postgresql-tooling.zip .
unzip cloudsql-postgresql-tooling.zip
- 現在の作業ディレクトリを、クローン作成したリポジトリのディレクトリに変更します。
cd cloudsql-postgresql-tooling/infrastructure/terraform
- 次のコマンドを実行して、リージョンとゾーンを
us-central1 と us-central1-a から、デフォルトで割り当てられているリージョンとゾーンに変更します。
export REGION={{{project_0.default_region|REGION}}}
sed -i "s/us-central1/$REGION/g" variables.tf
export ZONE={{{project_0.default_zone|ZONE}}}
sed -i "s/$REGION-a/$ZONE/g" variables.tf
-
init-db.sh スクリプトを実行します。
cd ~/cloudsql-postgresql-tooling
bash init-db.sh
これで、PostgreSQL インスタンスが作成され、ランダムなスキーマが追加されます。完了するまでに 10~15 分ほどかかります。
注: [Error: Failed to load "tfplan" as a plan file] が表示された場合は、init-db スクリプトを再実行してください。
すぐに次の出力が表示されます。
CREATE TABLE factory_warehouse69945.home17e97c57 ( house57588 DATE, paragraph64180 SMALLINT, ip_address61569 JSONB, date_time44962 REAL, food19478 JSONB, state8925 VARCHAR(25), cpf75444 REAL, date_time96090 SMALLINT, reason7955 CHAR(5), phone_number96292 INT, size97593 DATE, date_time609 CHAR(5), location70431 DATE )
COMPLETED
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
PostgreSQL データベースを作成する
サービス アカウントを設定する
- サービス アカウントを作成します。
gcloud iam service-accounts create postgresql2dc-credentials \
--display-name "Service Account for PostgreSQL to Data Catalog connector" \
--project $PROJECT_ID
- サービス アカウント キーを作成し、ダウンロードします。
gcloud iam service-accounts keys create "postgresql2dc-credentials.json" \
--iam-account "postgresql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com"
- サービス アカウントに Data Catalog の管理者ロールを追加します。
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member "serviceAccount:postgresql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com" \
--quiet \
--project $PROJECT_ID \
--role "roles/datacatalog.admin"
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
PostgreSQL のサービス アカウントを作成する
PostgreSQL から Dataplex へのコネクタを実行する
こちらの GitHub リポジトリから、PostgreSQL コネクタを自分で構築できます。
簡単に行えるように、このラボでは Docker イメージを使用します。
必要な変数は、Terraform 構成によって出力されました。
- ディレクトリを Terraform スクリプトの場所に変更します。
cd infrastructure/terraform/
- 環境変数を取得します。
public_ip_address=$(terraform output -raw public_ip_address)
username=$(terraform output -raw username)
password=$(terraform output -raw password)
database=$(terraform output -raw db_name)
- サンプルコードのルート ディレクトリに戻ります。
cd ~/cloudsql-postgresql-tooling
- コネクタを実行します。
docker run --rm --tty -v \
"$PWD":/data mesmacosta/postgresql2datacatalog:stable \
--datacatalog-project-id=$PROJECT_ID \
--datacatalog-location-id=$REGION \
--postgresql-host=$public_ip_address \
--postgresql-user=$username \
--postgresql-pass=$password \
--postgresql-database=$database
すぐに次の出力が表示されます。
============End postgresql-to-datacatalog============
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
PostgreSQL から Data Catalog へのコネクタを実行する
スクリプトの結果を確認する
-
Google Cloud コンソールのナビゲーション メニュー()で [すべてのプロダクトを表示] > [分析] > [Dataplex] の順にクリックして、[Dataplex] に移動します。
-
[タグ テンプレート] をクリックします。
次の postgresql タグ テンプレートが表示されます。

- [エントリ グループ] をクリックします。
次の postgresql エントリ グループが表示されます

-
postgresql エントリ グループをクリックします。コンソールには次のように表示されます。
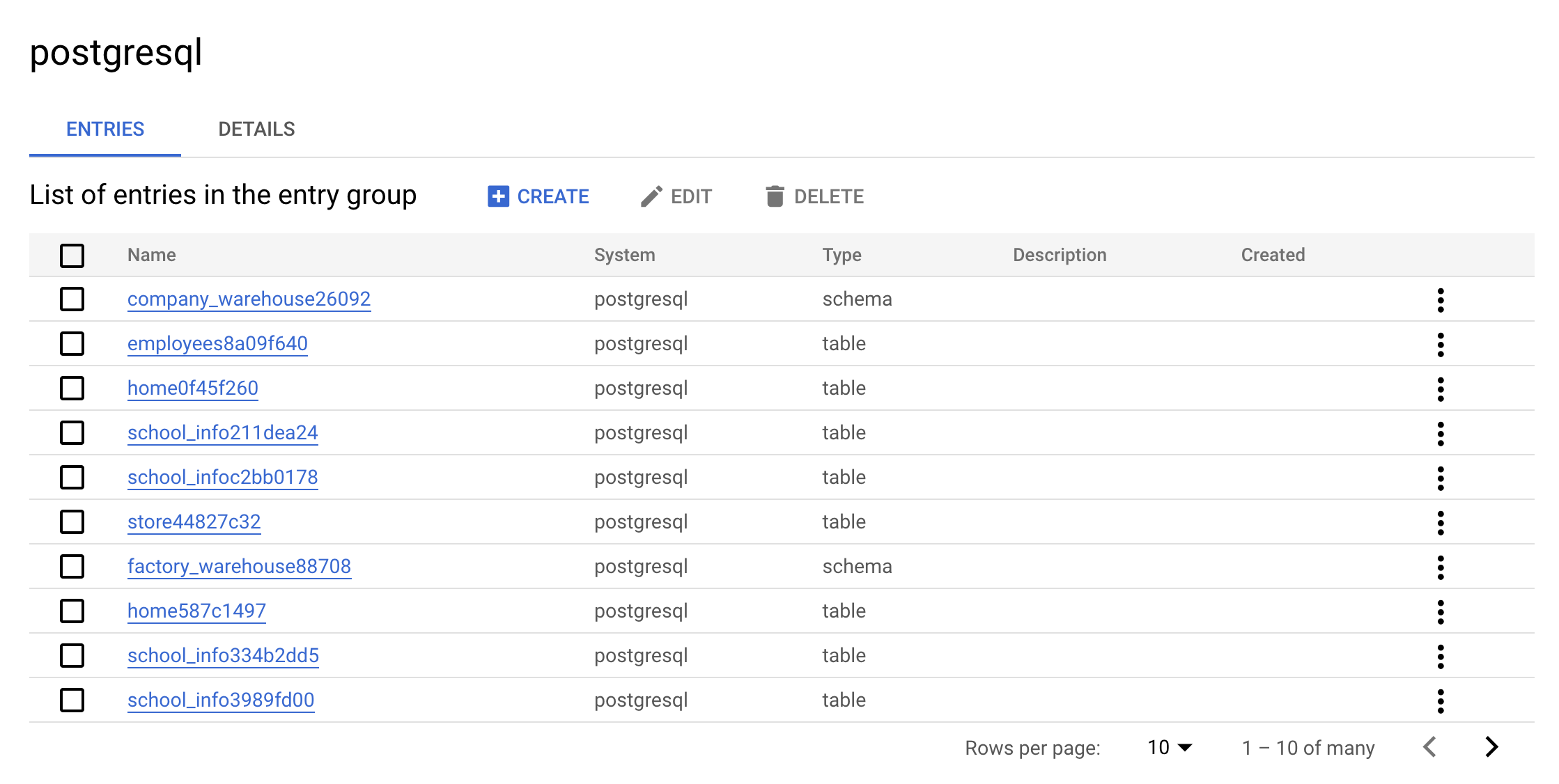
これはエントリ グループの実際の値です。postgresql に含まれるすべてのエントリを UI で確認できます。
-
warehouse エントリの一つをクリックします。カスタム エントリの詳細とタグを確認します。
![[カスタム エントリの詳細] タブページ](https://cdn.qwiklabs.com/647Ki3cjUJO%2BRy1%2Bl4OKVxWHgLG9bm3bJ5tHhZ7olC0%3D)
これはコネクタによって追加される実際の値です。これによって Dataplex 内でメタデータを検索できるようになります。
クリーンアップ
- 作成されたリソースを削除するには、次のコマンドを実行して PostgreSQL のメタデータを削除します。
./cleanup-db.sh
- クリーナー コンテナを実行します。
docker run --rm --tty -v \
"$PWD":/data mesmacosta/postgresql-datacatalog-cleaner:stable \
--datacatalog-project-ids=$PROJECT_ID \
--rdbms-type=postgresql \
--table-container-type=schema
- 最後に、PostgreSQL データベースを削除します。
./delete-db.sh
-
Dataplex メニューの [探索] で、[検索] ページをクリックします。
-
検索バーに「PostgreSQL」と入力し、[検索] をクリックします。
PostgreSQL のタグ テンプレートが結果に表示されなくなります。
Cloud Shell に次の出力が表示されることを確認したら、次に進みます。
Cloud SQL Instance deleted
COMPLETED
次に、同じ操作を MySQL インスタンスで行う方法を学習します。
タスク 3. MySQL から Dataplex
MySQL データベースを作成する
- Cloud Shell で次のコマンドを実行して、ホーム ディレクトリに戻ります。
cd
- 次のコマンドを実行してスクリプトをダウンロードし、MySQL Server インスタンスを作成してデータを追加します。
gsutil cp gs://spls/gsp814/cloudsql-mysql-tooling.zip .
unzip cloudsql-mysql-tooling.zip
- 現在の作業ディレクトリを、クローン作成したリポジトリのディレクトリに変更します。
cd cloudsql-mysql-tooling/infrastructure/terraform
- 次のコマンドを実行して、リージョンとゾーンを
us-central1 と us-central1-a から、デフォルトで割り当てられているリージョンとゾーンに変更します。
export REGION={{{project_0.default_region|REGION}}}
sed -i "s/us-central1/$REGION/g" variables.tf
export ZONE={{{project_0.default_zone|ZONE}}}
sed -i "s/$REGION-a/$ZONE/g" variables.tf
-
init-db.sh スクリプトを実行します。
cd ~/cloudsql-mysql-tooling
bash init-db.sh
これにより、MySQL インスタンスが作成され、ランダムなスキーマが追加されます。数分で次のような出力が表示されます。
CREATE TABLE factory_warehouse14342.persons88a5ebc4 ( address9634 TEXT, cpf12934 FLOAT, food88799 BOOL, food4761 LONGTEXT, credit_card44049 FLOAT, city8417 TINYINT, name76076 DATETIME, address19458 TIME, reason49953 DATETIME )
COMPLETED
注:
[Error: Failed to load "tfplan" as a plan file] が表示された場合は、init-db スクリプトを再実行してください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
MySQL データベースを作成する
サービス アカウントを設定する
- 次のコマンドを実行して、サービス アカウントを作成します。
gcloud iam service-accounts create mysql2dc-credentials \
--display-name "Service Account for MySQL to Data Catalog connector" \
--project $PROJECT_ID
- サービス アカウント キーを作成し、ダウンロードします。
gcloud iam service-accounts keys create "mysql2dc-credentials.json" \
--iam-account "mysql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com"
- サービス アカウントに Data Catalog の管理者ロールを追加します。
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member "serviceAccount:mysql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com" \
--quiet \
--project $PROJECT_ID \
--role "roles/datacatalog.admin"
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
MySQL のサービス アカウントを作成する
MySQL から Dataplex へのコネクタを実行する
こちらの GitHub リポジトリから、MySQL コネクタを自分で構築できます。
簡単に行えるように、このラボでは Docker イメージを使用します。
必要な変数は、Terraform 構成によって出力されました。
- ディレクトリを Terraform スクリプトの場所に変更します。
cd infrastructure/terraform/
- 環境変数を取得します。
public_ip_address=$(terraform output -raw public_ip_address)
username=$(terraform output -raw username)
password=$(terraform output -raw password)
database=$(terraform output -raw db_name)
- サンプルコードのルート ディレクトリに戻ります。
cd ~/cloudsql-mysql-tooling
- コネクタを実行します。
docker run --rm --tty -v \
"$PWD":/data mesmacosta/mysql2datacatalog:stable \
--datacatalog-project-id=$PROJECT_ID \
--datacatalog-location-id=$REGION \
--mysql-host=$public_ip_address \
--mysql-user=$username \
--mysql-pass=$password \
--mysql-database=$database
すぐに次の出力が表示されます。
============End mysql-to-datacatalog============
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
MySQL から Data Catalog へのコネクタを実行する
スクリプトの結果を確認する
-
Google Cloud コンソールのナビゲーション メニュー()で [すべてのプロダクトを表示] > [分析] > [Dataplex] の順にクリックして、[Dataplex] に移動します。
-
[タグ テンプレート] をクリックします。
次の mysql タグ テンプレートが表示されます。

- [エントリ グループ] をクリックします。
次の mysql エントリ グループが表示されます

-
mysql エントリ グループをクリックします。コンソールには次のように表示されます。
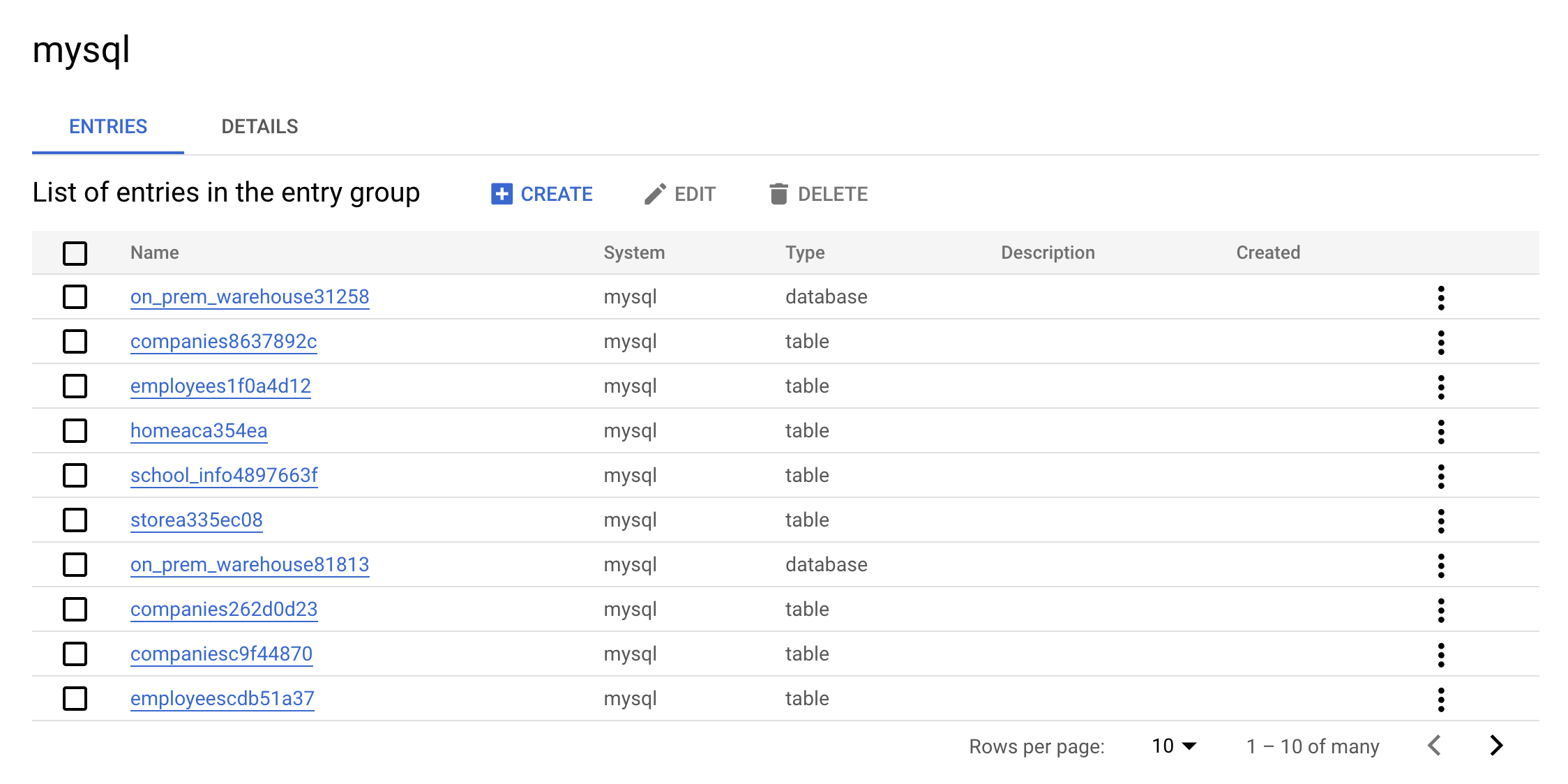
これはエントリ グループの実際の値です。MySQL に含まれるすべてのエントリを UI で確認できます。
-
warehouse エントリの一つをクリックします。カスタム エントリの詳細とタグを確認します。
これはコネクタによって追加される実際の値です。これによって Dataplex 内でメタデータを検索できるようになります。
クリーンアップ
- 作成されたリソースを削除するには、次のコマンドを実行して MySQL のメタデータを削除します。
./cleanup-db.sh
- クリーナー コンテナを実行します。
docker run --rm --tty -v \
"$PWD":/data mesmacosta/mysql-datacatalog-cleaner:stable \
--datacatalog-project-ids=$PROJECT_ID \
--rdbms-type=mysql \
--table-container-type=database
- 最後に、PostgreSQL データベースを削除します。
./delete-db.sh
Cloud Shell に次の出力が表示されることを確認したら、次に進みます。
Cloud SQL Instance deleted
COMPLETED
-
Dataplex メニューの [探索] で、[検索] ページをクリックします。
-
検索バーに「MySQL」と入力し、[検索] をクリックします。
MySQL のタグ テンプレートが結果に表示されなくなります。
お疲れさまでした
このラボでは、PostgreSQL と MySQL から Dataplex へのコネクタを構築して実行する方法を学習しました。また、Dataplex 内の Data Catalog で PostgreSQL と MySQL のエントリを検索する方法も学習しました。これらの知識を活かして、独自のコネクタを構築しましょう。
次のステップと詳細情報
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 10 月 24 日
ラボの最終テスト日: 2024 年 10 月 24 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





