Data Catalog est obsolète et ne sera plus disponible à partir du 30 janvier 2026. Vous pouvez toujours effectuer cet atelier si vous le souhaitez.
Pour savoir comment transférer vos utilisateurs, vos charges de travail et votre contenu Data Catalog vers le catalogue Dataplex, consultez "Passer de Data Catalog au catalogue Dataplex" (https://cloud.google.com/dataplex/docs/transition-to-dataplex-catalog).
GSP814

Présentation
Dataplex est une data fabric intelligente qui permet aux entreprises de découvrir, de gérer, de surveiller et de gouverner leurs données de façon centralisée sur des lacs, des entrepôts et des magasins de données pour optimiser les analyses à grande échelle.
Data Catalog est un service de gestion des métadonnées entièrement géré et évolutif au sein de Dataplex. Il offre une interface de recherche simple et intuitive pour la découverte des données, un système de catalogage flexible et performant pour la capture de métadonnées techniques et métier, ainsi qu'une base solide en termes de sécurité et de conformité avec les intégrations Cloud Data Loss Prevention (qui fait partie de Sensitive Data Protection) et Identity and Access Management (IAM).
Utiliser Data Catalog
En utilisant Data Catalog dans Dataplex, vous pouvez rechercher des éléments auxquels vous avez accès et taguer des éléments de données pour faciliter la découverte et le contrôle des accès. Les tags vous permettent d'associer des champs de métadonnées personnalisés à des éléments de données spécifiques pour en simplifier l'identification et la récupération : vous pouvez par exemple taguer certains éléments comme contenant des données protégées ou sensibles. Vous pouvez aussi créer des modèles de tag réutilisables pour attribuer rapidement les mêmes tags à différents éléments de données.
Points abordés
Dans cet atelier, vous allez apprendre à :
- activer l'API Data Catalog ;
- configurer des connecteurs Dataplex pour PostgreSQL et MySQL ;
- rechercher des entrées PostgreSQL et MySQL dans Data Catalog de Dataplex.
Prérequis
Remarque : Avant de commencer cet atelier, déconnectez-vous de votre compte Gmail personnel ou professionnel, ou lancez l'atelier dans une fenêtre de navigation privée. Cela vous évitera d'être connecté au mauvais compte.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Des identifiants temporaires vous sont fournis pour vous permettre de vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- Vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome).
Remarque : Ouvrez une fenêtre de navigateur en mode incognito (recommandé) ou de navigation privée pour effectuer cet atelier. Vous éviterez ainsi les conflits entre votre compte personnel et le compte temporaire de participant, qui pourraient entraîner des frais supplémentaires facturés sur votre compte personnel.
- Vous disposez d'un temps limité. N'oubliez pas qu'une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Remarque : Utilisez uniquement le compte de participant pour cet atelier. Si vous utilisez un autre compte Google Cloud, des frais peuvent être facturés à ce compte.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, une boîte de dialogue s'affiche pour vous permettre de sélectionner un mode de paiement.
Sur la gauche, vous trouverez le panneau "Détails concernant l'atelier", qui contient les éléments suivants :
- Le bouton "Ouvrir la console Google Cloud"
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page "Se connecter" dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte.
-
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}}
Vous trouverez également le nom d'utilisateur dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}}
Vous trouverez également le mot de passe dans le panneau "Détails concernant l'atelier".
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud.
Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés.
-
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais sans frais.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.
Remarque : Pour accéder aux produits et services Google Cloud, cliquez sur le menu de navigation ou saisissez le nom du service ou du produit dans le champ Recherche.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
-
Cliquez sur Activer Cloud Shell  en haut de la console Google Cloud.
en haut de la console Google Cloud.
-
Passez les fenêtres suivantes :
- Accédez à la fenêtre d'informations de Cloud Shell.
- Autorisez Cloud Shell à utiliser vos identifiants pour effectuer des appels d'API Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET : . Le résultat contient une ligne qui déclare l'ID_PROJET pour cette session :
Your Cloud Platform project in this session is set to {{{project_0.project_id | "PROJECT_ID"}}}
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
gcloud auth list
- Cliquez sur Autoriser.
Résultat :
ACTIVE: *
ACCOUNT: {{{user_0.username | "ACCOUNT"}}}
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
gcloud config list project
Résultat :
[core]
project = {{{project_0.project_id | "PROJECT_ID"}}}
Remarque : Pour consulter la documentation complète sur gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Activer l'API Data Catalog
-
Dans la console Google Cloud, cliquez sur le menu de navigation ( ) > API et services > Bibliothèque.
) > API et services > Bibliothèque.
-
Dans la barre de recherche, saisissez Data Catalog, puis sélectionnez l'API Data Catalog Google Cloud.
-
Cliquez sur Activer.
Remarque : Si une erreur "Échec de l'action" s'affiche lorsque vous essayez d'activer l'API Data Catalog, suivez ces étapes : cliquez sur Fermer, actualisez votre onglet de navigateur, puis cliquez à nouveau sur Activer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Activer l'API Data Catalog
Tâche 2 : PostgreSQL vers Dataplex
Créer une variable pour l'ID du projet
- Dans Cloud Shell, exécutez la commande suivante pour définir l'ID de votre projet en tant que variable d'environnement :
export PROJECT_ID=$(gcloud config get-value project)
Créer la base de données PostgreSQL
- Exécutez la commande suivante pour cloner le dépôt GitHub :
gsutil cp gs://spls/gsp814/cloudsql-postgresql-tooling.zip .
unzip cloudsql-postgresql-tooling.zip
- Passez de votre répertoire de travail actuel au répertoire du dépôt cloné :
cd cloudsql-postgresql-tooling/infrastructure/terraform
- Exécutez les commandes suivantes pour remplacer la région et la zone
us-central1 et us-central1-a par celles qui vous ont été attribuées par défaut :
export REGION={{{project_0.default_region|REGION}}}
sed -i "s/us-central1/$REGION/g" variables.tf
export ZONE={{{project_0.default_zone|ZONE}}}
sed -i "s/$REGION-a/$ZONE/g" variables.tf
- Exécutez maintenant le script
init-db.sh :
cd ~/cloudsql-postgresql-tooling
bash init-db.sh
Votre instance PostgreSQL sera créée et renseignée selon un schéma aléatoire. Cette opération peut prendre entre 10 et 15 minutes.
Remarque :
Si le message Error: Failed to load "tfplan" as a plan file apparaît, relancez le script init-db.
Vous devriez rapidement obtenir le résultat suivant :
CREATE TABLE factory_warehouse69945.home17e97c57 ( house57588 DATE, paragraph64180 SMALLINT, ip_address61569 JSONB, date_time44962 REAL, food19478 JSONB, state8925 VARCHAR(25), cpf75444 REAL, date_time96090 SMALLINT, reason7955 CHAR(5), phone_number96292 INT, size97593 DATE, date_time609 CHAR(5), location70431 DATE )
COMPLETED
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer la base de données PostgreSQL
Configurer le compte de service
- Créez un compte de service :
gcloud iam service-accounts create postgresql2dc-credentials \
--display-name "Service Account for PostgreSQL to Data Catalog connector" \
--project $PROJECT_ID
- Ensuite, créez et téléchargez la clé du compte de service :
gcloud iam service-accounts keys create "postgresql2dc-credentials.json" \
--iam-account "postgresql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com"
- Accordez le rôle d'administrateur Data Catalog au compte de service :
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member "serviceAccount:postgresql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com" \
--quiet \
--project $PROJECT_ID \
--role "roles/datacatalog.admin"
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un compte de service pour PostgreSQL
Exécuter le connecteur PostgreSQL vers Dataplex
Vous pouvez créer le connecteur PostgreSQL manuellement à partir de ce dépôt GitHub.
Pour en faciliter l'utilisation, cet atelier fait appel à une image Docker.
Les variables nécessaires ont été générées par la configuration Terraform.
- Modifiez le répertoire dans lequel se trouvent les scripts Terraform :
cd infrastructure/terraform/
- Récupérez les variables d'environnement :
public_ip_address=$(terraform output -raw public_ip_address)
username=$(terraform output -raw username)
password=$(terraform output -raw password)
database=$(terraform output -raw db_name)
- Revenez au répertoire racine de l'exemple de code :
cd ~/cloudsql-postgresql-tooling
- Exécutez le connecteur :
docker run --rm --tty -v \
"$PWD":/data mesmacosta/postgresql2datacatalog:stable \
--datacatalog-project-id=$PROJECT_ID \
--datacatalog-location-id=$REGION \
--postgresql-host=$public_ip_address \
--postgresql-user=$username \
--postgresql-pass=$password \
--postgresql-database=$database
Vous devriez rapidement obtenir le résultat suivant :
============End postgresql-to-datacatalog============
Cliquez sur Vérifier ma progression pour valider l'objectif.
Exécuter un connecteur PostgreSQL vers Data Catalog
Vérifier les résultats du script
-
Accédez à Dataplex dans la console Google Cloud en cliquant sur le menu de navigation () > Afficher tous les produits > Analyse > Dataplex.
-
Cliquez sur Modèles de tag.
Les modèles de tag postgresql suivants devraient apparaître :

- Cliquez sur Groupes d'entrées.
Ce groupe d'entrées postgresql devrait apparaître :

- Cliquez à présent sur le groupe d'entrées
postgresql. La console doit se présenter comme suit :
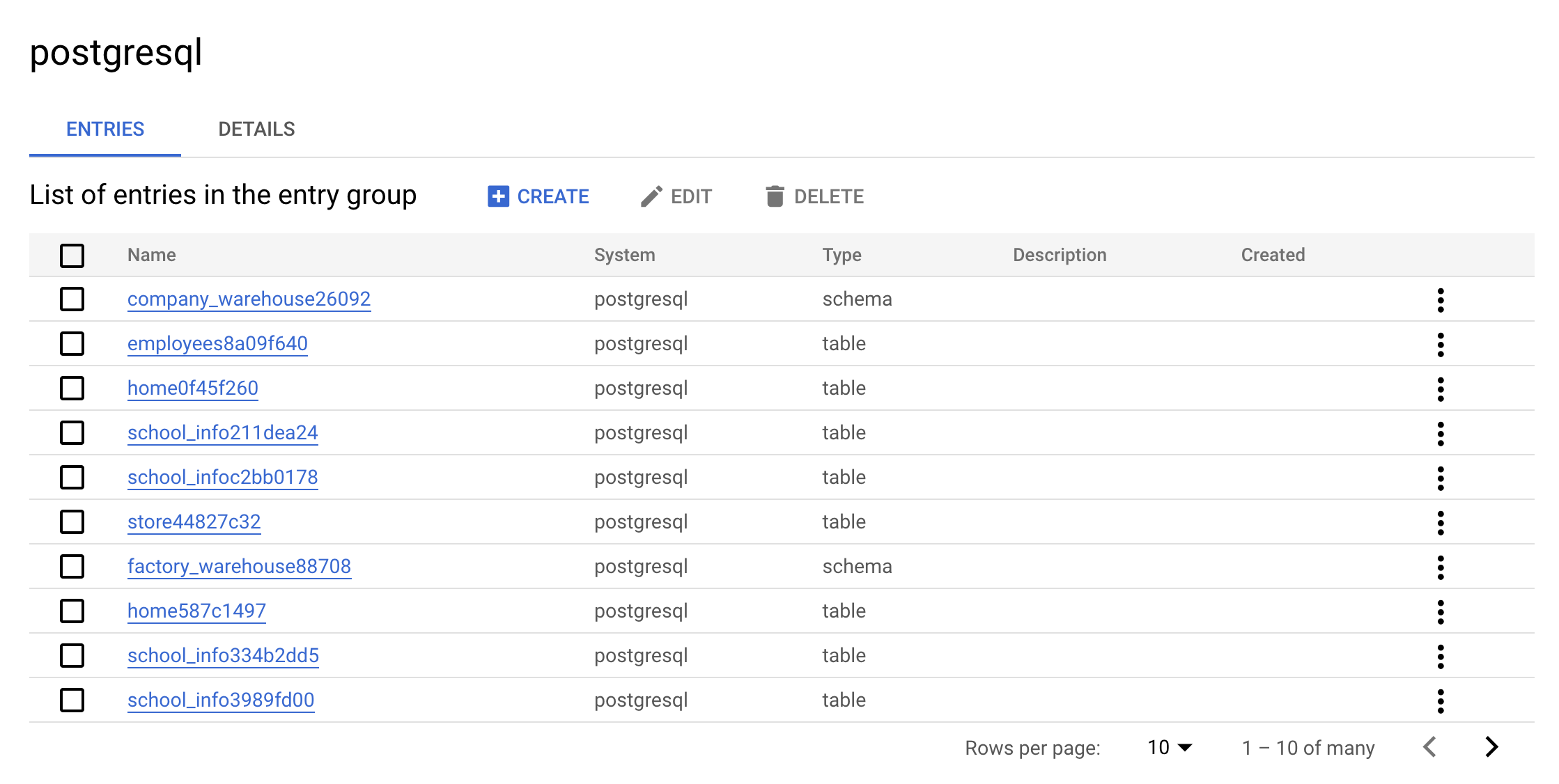
Voilà tout l'intérêt d'un groupe d'entrées : il vous permet d'afficher l'ensemble des entrées qui appartiennent à postgresql dans l'interface utilisateur.
- Cliquez sur une entrée
warehouse. Observez les sections "Détails de l'entrée personnalisée" et "Tags" :
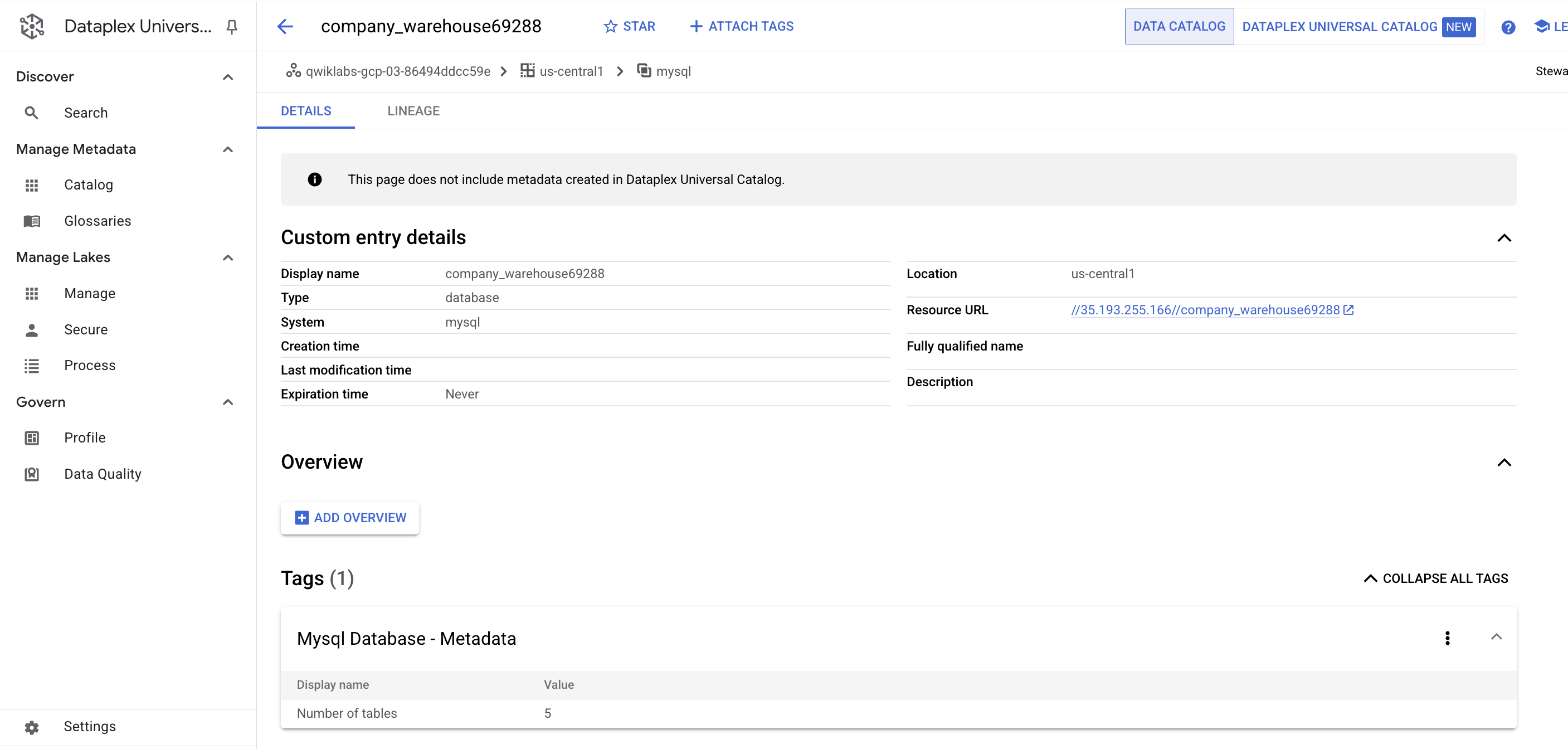
Voilà tout l'intérêt du connecteur : il vous permet d'inclure les métadonnées dans l'index de recherche de Dataplex.
Effectuer un nettoyage
- Exécutez la commande suivante pour supprimer les métadonnées PostgreSQL qui ont été créées :
./cleanup-db.sh
- Exécutez maintenant le conteneur responsable du nettoyage :
docker run --rm --tty -v \
"$PWD":/data mesmacosta/postgresql-datacatalog-cleaner:stable \
--datacatalog-project-ids=$PROJECT_ID \
--rdbms-type=postgresql \
--table-container-type=schema
- Enfin, supprimez la base de données PostgreSQL :
./delete-db.sh
-
Dans le menu Dataplex, sous Découvrir, cliquez sur la page Recherche.
-
Dans la barre de recherche, saisissez PostgreSQL, puis cliquez sur Rechercher.
Les modèles de tag PostgreSQL n'apparaissent plus dans les résultats :
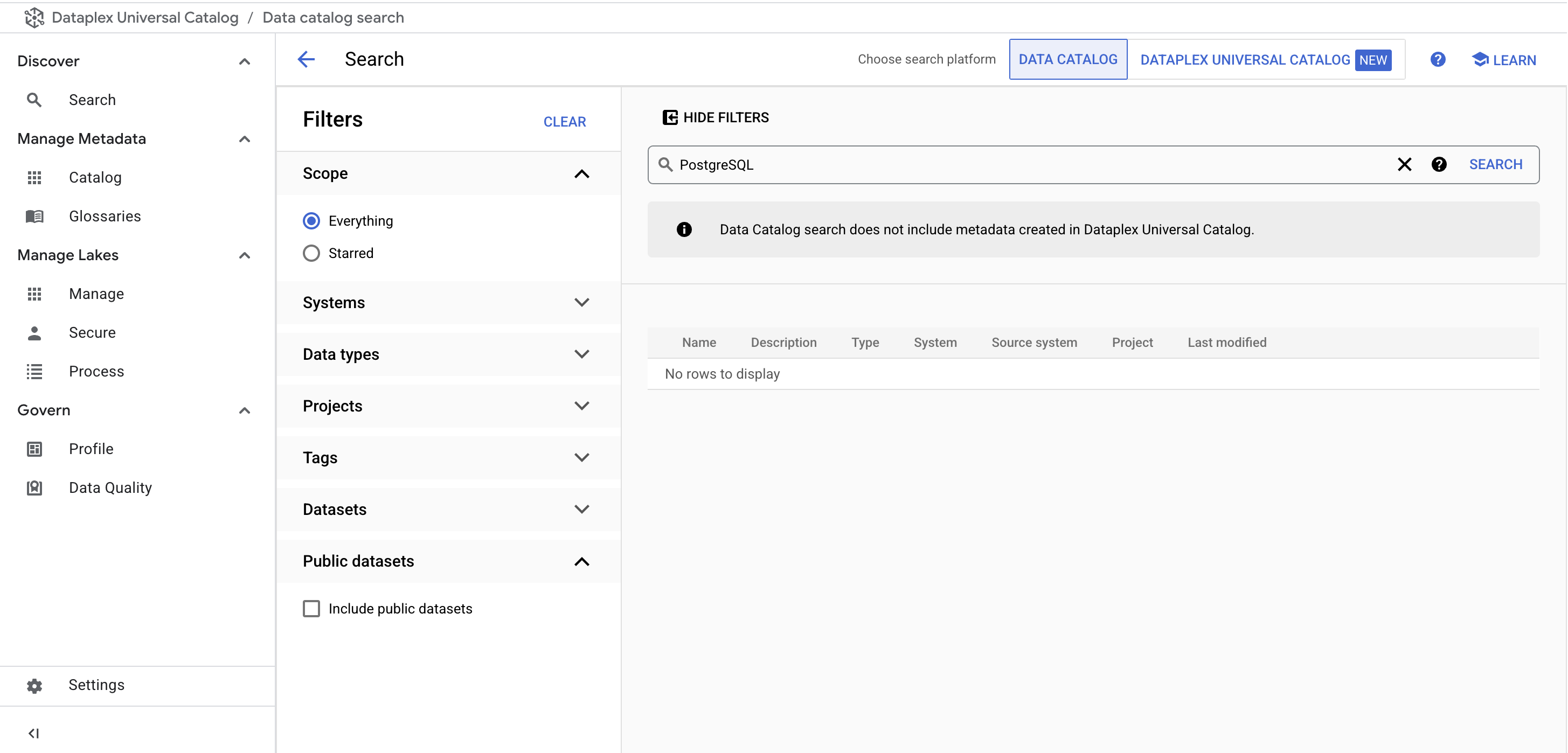
Avant de continuer, vérifiez que vous obtenez le résultat suivant dans Cloud Shell :
Cloud SQL Instance deleted
COMPLETED
Vous allez ensuite apprendre à réaliser la même opération avec une instance MySQL.
Tâche 3 : MySQL vers Dataplex
Créer la base de données MySQL
- Exécutez la commande suivante dans Cloud Shell pour revenir à votre répertoire d'accueil :
cd
- Exécutez la commande suivante afin de télécharger les scripts pour créer et renseigner votre instance MySQL :
gsutil cp gs://spls/gsp814/cloudsql-mysql-tooling.zip .
unzip cloudsql-mysql-tooling.zip
- Passez de votre répertoire de travail actuel au répertoire du dépôt cloné :
cd cloudsql-mysql-tooling/infrastructure/terraform
- Exécutez les commandes suivantes pour remplacer la région et la zone
us-central1 et us-central1-a par celles qui vous ont été attribuées par défaut :
export REGION={{{project_0.default_region|REGION}}}
sed -i "s/us-central1/$REGION/g" variables.tf
export ZONE={{{project_0.default_zone|ZONE}}}
sed -i "s/$REGION-a/$ZONE/g" variables.tf
- Exécutez maintenant le script
init-db.sh :
cd ~/cloudsql-mysql-tooling
bash init-db.sh
Votre instance MySQL sera créée et renseignée selon un schéma aléatoire. Vous devriez obtenir le résultat suivant au bout de quelques minutes :
CREATE TABLE factory_warehouse14342.persons88a5ebc4 ( address9634 TEXT, cpf12934 FLOAT, food88799 BOOL, food4761 LONGTEXT, credit_card44049 FLOAT, city8417 TINYINT, name76076 DATETIME, address19458 TIME, reason49953 DATETIME )
COMPLETED
Remarque :
Si le message Error: Failed to load "tfplan" as a plan file apparaît, réexécutez le script init-db.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer la base de données MySQL
Configurer le compte de service
- Exécutez cette commande pour créer un compte de service :
gcloud iam service-accounts create mysql2dc-credentials \
--display-name "Service Account for MySQL to Data Catalog connector" \
--project $PROJECT_ID
- Ensuite, créez et téléchargez la clé du compte de service :
gcloud iam service-accounts keys create "mysql2dc-credentials.json" \
--iam-account "mysql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com"
- Accordez le rôle d'administrateur Data Catalog au compte de service :
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member "serviceAccount:mysql2dc-credentials@$PROJECT_ID.iam.gserviceaccount.com" \
--quiet \
--project $PROJECT_ID \
--role "roles/datacatalog.admin"
Cliquez sur Vérifier ma progression pour valider l'objectif.
Créer un compte de service pour MySQL
Exécuter le connecteur MySQL vers Dataplex
Vous pouvez créer le connecteur MySQL manuellement à partir de ce dépôt GitHub.
Pour en faciliter l'utilisation, cet atelier fait appel à une image Docker.
Les variables nécessaires ont été générées par la configuration Terraform.
- Modifiez le répertoire dans lequel se trouvent les scripts Terraform :
cd infrastructure/terraform/
- Récupérez les variables d'environnement :
public_ip_address=$(terraform output -raw public_ip_address)
username=$(terraform output -raw username)
password=$(terraform output -raw password)
database=$(terraform output -raw db_name)
- Revenez au répertoire racine de l'exemple de code :
cd ~/cloudsql-mysql-tooling
- Exécutez le connecteur :
docker run --rm --tty -v \
"$PWD":/data mesmacosta/mysql2datacatalog:stable \
--datacatalog-project-id=$PROJECT_ID \
--datacatalog-location-id=$REGION \
--mysql-host=$public_ip_address \
--mysql-user=$username \
--mysql-pass=$password \
--mysql-database=$database
Vous devriez rapidement obtenir le résultat suivant :
============End mysql-to-datacatalog============
Cliquez sur Vérifier ma progression pour valider l'objectif.
Exécuter un connecteur MySQL vers Data Catalog
Vérifier les résultats du script
-
Accédez à Dataplex dans la console Google Cloud en cliquant sur le menu de navigation () > Afficher tous les produits > Analyse > Dataplex.
-
Cliquez sur Modèles de tag.
Les modèles de tag mysql suivants devraient apparaître :

- Cliquez sur Groupes d'entrées.
Ce groupe d'entrées mysql devrait apparaître :

- Cliquez à présent sur le groupe d'entrées
mysql. La console doit se présenter comme suit :
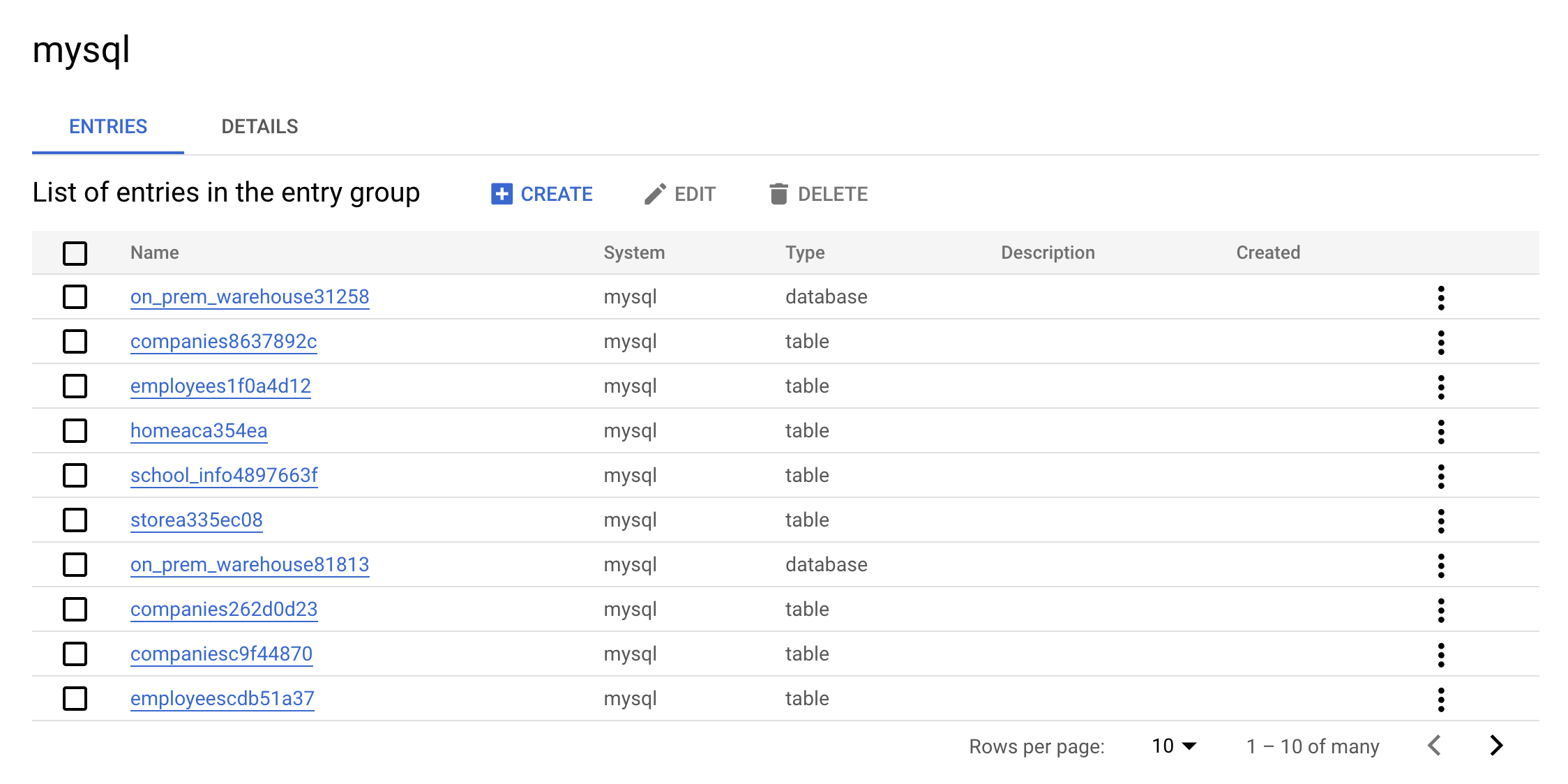
Voilà tout l'intérêt d'un groupe d'entrées : il vous permet d'afficher l'ensemble des entrées qui appartiennent à MySQL dans l'interface utilisateur.
- Cliquez sur une entrée
warehouse. Observez les sections "Détails de l'entrée personnalisée" et "Tags".
Voilà tout l'intérêt du connecteur : il vous permet d'inclure les métadonnées dans l'index de recherche de Dataplex.
Effectuer un nettoyage
- Exécutez la commande suivante pour supprimer les métadonnées MySQL qui ont été créées :
./cleanup-db.sh
- Exécutez maintenant le conteneur responsable du nettoyage :
docker run --rm --tty -v \
"$PWD":/data mesmacosta/mysql-datacatalog-cleaner:stable \
--datacatalog-project-ids=$PROJECT_ID \
--rdbms-type=mysql \
--table-container-type=database
- Enfin, supprimez la base de données PostgreSQL :
./delete-db.sh
Avant de continuer, vérifiez que vous obtenez le résultat suivant dans Cloud Shell :
Cloud SQL Instance deleted
COMPLETED
-
Dans le menu Dataplex, sous Découvrir, cliquez sur la page Recherche.
-
Dans la barre de recherche, saisissez MySQL, puis cliquez sur Rechercher.
Les modèles de tag MySQL n'apparaissent plus dans les résultats.
Félicitations !
Dans cet atelier, vous avez appris à créer et à exécuter des connecteurs PostgreSQL et MySQL vers Dataplex. Vous avez également découvert comment rechercher des entrées PostgreSQL et MySQL dans Data Catalog de Dataplex. Vous pouvez désormais utiliser ces connaissances pour créer vos propres connecteurs.
Étapes suivantes et informations supplémentaires
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 24 octobre 2024
Dernier test de l'atelier : 24 octobre 2024
Copyright 2025 Google LLC. Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.





