
![[Cloud Pub/Sub Trigger] から [Data Mapping]、[Send Email] へとつながる矢印](https://cdn.qwiklabs.com/nIEIGRLw6mQXKasQSnb7jUNfxGNRt5%2BmnDjVKjcZUYU%3D)

始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
Create and configure a BigQuery remote model
/ 20
Grant access to BigQuery and Pub/Sub resources
/ 20
Create and configure an Application Integration trigger
/ 20
Create a continuous query in BigQuery that generates email text
/ 20
Add data to the abandoned carts table to test the continuous query
/ 20
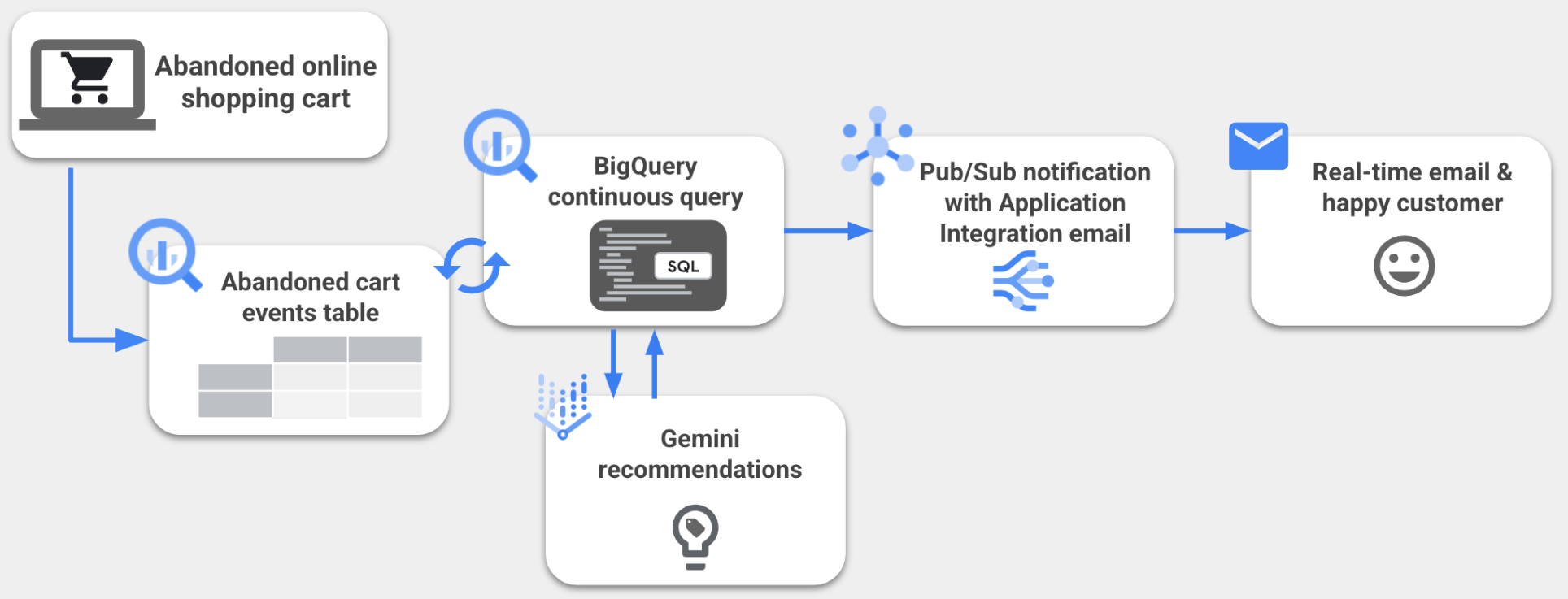
顧客エンゲージメント システムの構築は複雑になることが多く、特殊なツールが必要にある場合もあります。この構築を SQL ステートメントのような簡単な方法で行えるとしたら、どうでしょうか。これを実現したのが、BigQuery の継続的クエリです。
想像してみてください。自社の素晴らしいウェブサイトに見込み顧客を呼び込んで、顧客が商品をショッピング カートに入れてくれたとします。しかし、顧客は購入を完了することなく姿を消してしまいました。この問題を解決する方法として、BigQuery の継続的クエリと Gemini を使用してカスタムメールを作成すれば、リアルタイムのエンゲージメントによって顧客の関心を取り戻すことができます。
BigQuery の継続的クエリは継続的に実行される SQL ステートメントであるため、受信データを BigQuery でリアルタイムに分析できます。継続的クエリを使用すると、分析情報の作成と即時対応、リアルタイムの ML 推論の適用と生成されたコンテンツの使用、他のプラットフォームへのデータのレプリケーションなど、時間的制約のあるタスクを実行できます。そのため、アプリケーションの判断ロジックでイベント ドリブンのデータ処理エンジンとして BigQuery を使用できます。BigQuery の継続的クエリを活用することで、リアルタイムの AI ユースケースを実現できます。たとえば、Gemini などの生成 AI モデルを使用して、顧客の選択内容に応じてパーソナライズされたテキストを生成できます。
このラボでは、BigQuery の継続的クエリ、Gemini モデル、Pub/Sub、Application Integration トリガーを使用してパーソナライズされたメールの内容を生成し、送信する方法を学習します。具体的には、放棄されたショッピング カートのレコードを保存する BigQuery テーブルをモニタリングし、新たに放棄されたカートの情報を Gemini に送信して、対象の顧客に合わせてプロモーション メールを生成する BigQuery 継続的クエリを作成します。パーソナライズされたメールの内容は BigQuery から Pub/Sub トピックにエクスポートされ、受信した Pub/Sub メッセージごとに構成済みの Application Integration トリガーによってメールが送信されます。
このラボでは、次の方法について学びます。
こちらの説明をお読みください。ラボには時間制限があり、一時停止することはできません。タイマーは、Google Cloud のリソースを利用できる時間を示しており、[ラボを開始] をクリックするとスタートします。
このハンズオンラボでは、シミュレーションやデモ環境ではなく実際のクラウド環境を使って、ラボのアクティビティを行います。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるダイアログでお支払い方法を選択してください。 左側の [ラボの詳細] ペインには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースがスピンアップし、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] ペインでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] ペインでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

このタスクでは、continuous_queries という BigQuery データセットと、放棄されたショッピング カート情報が含まれる abandoned_carts というテーブルなど、いくつかのリソースが事前に作成されています。
このタスクでは、BigQuery ML リモートモデル(エンドポイントとして Gemini 2.0 Flash を使用)などの追加の BigQuery リソースを作成して構成し、ワークフローに応じてパーソナライズされたメールの内容を生成します。
Google Cloud コンソールで、ナビゲーション メニュー(
[エクスプローラ] ペインで [+ 追加] をクリックし、[外部データソースへの接続] をクリックします。
[接続タイプ] で、[Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)] を選択します。
[接続 ID] に「continuous-queries-connection」と入力します。
[ロケーション タイプ] で、[リージョン] > [
[接続を作成] をクリックし、(ページの下部にあるメッセージ内の)[接続に移動] をクリックします。
[接続情報] ページでサービス アカウント ID をコピーし、次のセクションで使用できるようにします。
例: bqcx-1054723899402-whbp@gcp-sa-bigquery-condel.iam.gserviceaccount.com
Google Cloud コンソールのナビゲーション メニュー(
[アクセス権を付与] をクリックします。
[新しいプリンシパル] に、前のセクションでコピーしたサービス アカウント ID(例: bqcx-1054723899402-whbp@gcp-sa-bigquery-condel.iam.gserviceaccount.com)を入力します。
[ロールを選択] で、[Vertex AI] > [Vertex AI ユーザー] を選択します。
[保存] をクリックします。
Google Cloud コンソールで、ナビゲーション メニュー(
[無題のクエリ] をクリックして、空のクエリ ウィンドウにアクセスします。
BigQuery ML モデルを作成するための以下のクエリをコピーして貼り付け、[実行] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このタスクでは、recapture_customer という Pub/Sub トピックと bq-continuous-query-sa@
このタスクでは、カスタム サービス アカウントに BigQuery データセット、リモートモデル、Pub/Sub トピックへのアクセス権を付与します。これらのアクセス権は、後続のタスクでパーソナライズされたメールを生成して送信する際に使用します。
Google Cloud コンソールで、ナビゲーション メニュー(
[エクスプローラ] ペインで、
[外部接続] を開き、[
[接続情報] ページで、[共有] をクリックします。
[プリンシパルを追加] をクリックします。
[新しいプリンシパル] で、カスタム サービス アカウント ID(bq-continuous-query-sa@
[ロールを選択] で、[BigQuery] > [BigQuery Connection ユーザー] を選択します。
[保存]、[閉じる] の順にクリックします。
[エクスプローラ] ペインで、放棄されたカートのテーブルを含むデータセットの名前(continuous_queries)をクリックします。
[データセット情報] ページで [共有] をクリックし、[権限] を選択します。
[プリンシパルを追加] をクリックします。
[新しいプリンシパル] で、カスタム サービス アカウント ID(bq-continuous-query-sa@
[ロールを選択] で、[BigQuery] > [BigQuery データ編集者] を選択します。
[保存]、[閉じる] の順にクリックします。
Google Cloud コンソールで、ナビゲーション メニュー(
recapture_customer の行で、[その他の操作](縦に並んだ 3 つの点)をクリックし、[権限を表示] を選択します。
[プリンシパルを追加] をクリックします。
[新しいプリンシパル] で、カスタム サービス アカウント ID(bq-continuous-query-sa@
[ロールを選択] で、[Pub/Sub] > [Pub/Sub 閲覧者] を選択します。
[別のロールを追加] をクリックします。
[ロールを選択] で、[Pub/Sub] > [Pub/Sub パブリッシャー] を選択します。
[保存] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Application Integration は Google Cloud の Integration Platform as a Service(iPaaS)ソリューションです。特定の業務を支えるために統合が必要な複数のアプリケーションとデータを連携させ、管理する(統合と呼ばれます)ための一連のツールを備えています。トリガーとは、統合においてタスクまたは一連のタスクを開始する外部イベントです。たとえば、Pub/Sub トピックのイベントに基づく Pub/Sub トリガーなどです。トリガーは、統合のエントリ ポイントと考えることができます。トリガーに結びついたイベントにより、トリガーに関連付けられたタスクが実行されます。
このタスクでは、Pub/Sub トピックに新しいメッセージが送信されたときに統合を実行する Application Integration トリガーを作成して構成します。統合の出力は、ショッピング カートを放棄したお客様に送信されるメールです。
Google Cloud コンソールで、(ページ上部にある)検索バーに「Application Integration」と入力し、結果リストの [Application Integration] をクリックします。
[Get started with Application Integration] ページの [リージョン] で [
[Quick setup] をクリックして、必要な API を有効にします。
[Create integration] をクリックし、統合の名前として次の値を入力します。abandoned-shopping-carts-integration
[CREATE] をクリックします。
abandoned-shopping-carts-integration のページで(上部にある)[Triggers] をクリックします。
[Cloud Pub/Sub] を選択し、キャンバスをクリックして Pub/Sub トリガーを追加します。
トリガーの詳細ペインの [Trigger Input] > [Pub/Sub topic] に、事前に作成した Pub/Sub トピックへのパスを追加します。
ID がリストに表示されない場合は、[Refresh list] をクリックします。
[Grant the necessary roles] という警告が表示された場合は、[Grant] をクリックします。
キャンバスの上部で([Triggers] の隣にある)[Tasks] をクリックします。
検索バーに「Data Mapping」と入力します。
結果から [Data Mapping] を選択し、キャンバスをクリックして [Cloud Pub/Sub Trigger] の下にデータ マッピング タスクを追加します。
[Cloud Pub/Sub Trigger] の下の接続点をクリックしてカーソルをドラッグし、[Data Mapping] の上の接続点につなげます。
これで、[Cloud Pub/Sub Trigger] の下から [Data Mapping] の上に矢印がつながりました。
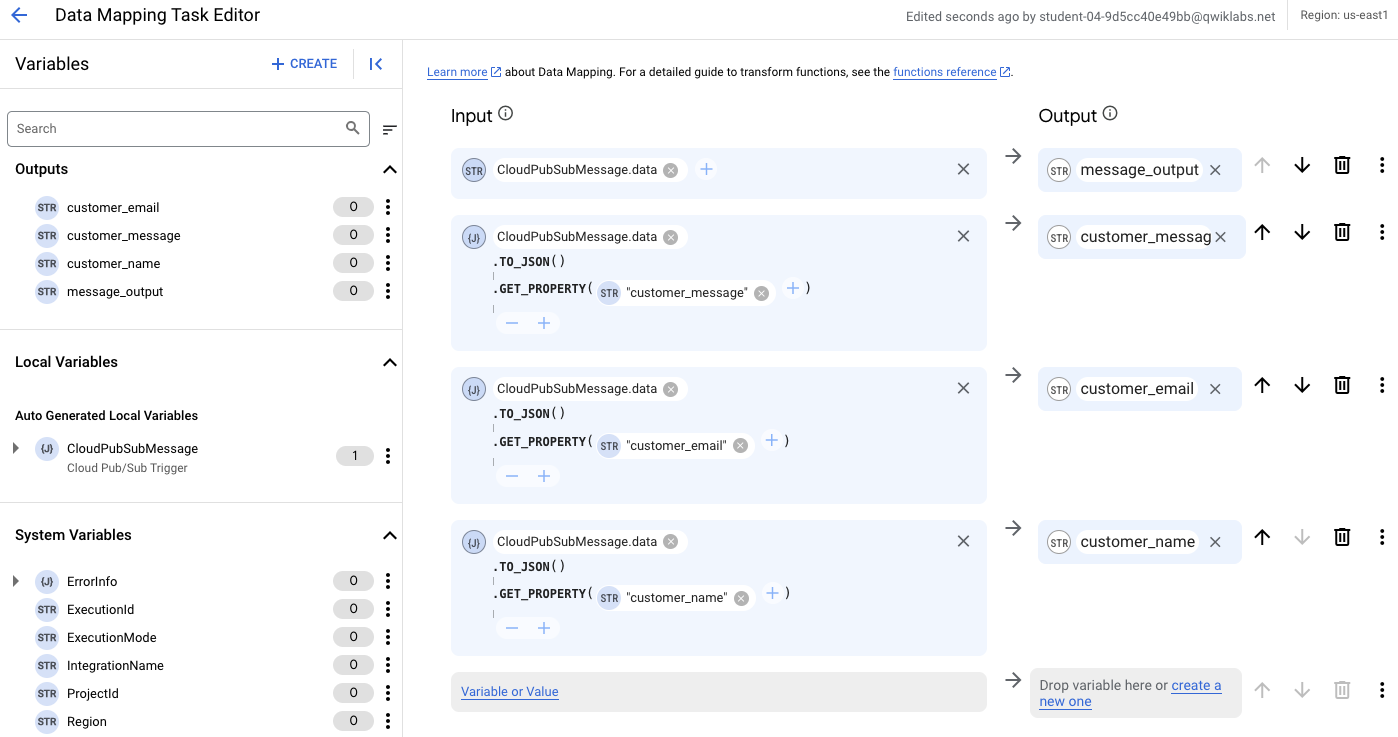
次のステップでは、CloudPubSubMessage.data 型の 4 つの入力変数を作成します。
[Input] で [Variable or Value] をクリックします。
[Variable]、[CloudPubSubMessage.data] の順に選択します。[Save] をクリックします。
[Output] で [Create a new one] をクリックします。
[Name] に「message_output」と入力します。
[Variable type] で [Output from integration] を選択します。
[Data type] で [String] を選択します。
[Blank default value means] で、[Empty string] をオンにします。
[Create] をクリックします。
Input に関数が含まれない変数を 1 つ作成しました。
次に、Input に 2 つの関数が含まれる別の変数を作成します。
[Input] で [Variable or Value] をクリックします。
[Variable]、[CloudPubSubMessage.data] の順に選択します。[Save] をクリックします。
2 つ目の変数の横にある [Add a function](+ アイコン)をクリックし、[TO_JSON() -> JSON] を選択します。
2 つ目の変数の [Add a function](+ アイコン)を再度クリックし、[GET_PROPERTY(String) -> JSON] を選択します。
[.GET_PROPERTY] の横にある [Variable or Value] をクリックします。
[Value] を選択し、「customer_message」と入力します。
この変数の同じ行で、[Output] の下にある [Create a new one] をクリックします。
[Name] に「customer_message」と入力します。
[Variable type] で [Output from integration] を選択します。
[Data type] で [String] を選択します。
[Blank default value means] で、[Empty string] をオンにします。
[Create] をクリックします。
| GET_PROPERTY() の値 | 出力名 |
|---|---|
| customer_email | customer_email |
| customer_name | customer_name |
この Application Integration トリガーに対して、message_output、customer_message、customer_email、customer_name の 4 つのデータ マッピング変数が構成されました。
画面上部の [Data Mapping Task Editor] の横にある戻る矢印(<-)をクリックして、キャンバスに戻ります。
キャンバスの上部で([Triggers] の隣にある)[Tasks] をクリックします。
検索バーに「Send Email」と入力します。
結果から [Send Email] を選択し、キャンバスをクリックして [Data Mapping] の下にメール送信タスクを追加します。
[Data Mapping] の下の接続点をクリックしてカーソルをドラッグし、[Send Email] の上の接続点につなげます。
[Cloud Pub/Sub Trigger] を [Data Mapping] につなげる最初の矢印に加えて、[Data Mapping] の下から [Send Email] の上につながる 2 つ目の矢印が追加されました。
キャンバスで [Send Email] の項目をクリックして、詳細を表示します。
[To Recipient(s)] で [Variable] をクリックします。「customer_email」と入力し、検索結果からその変数を選択します。
赤色の警告が表示された場合は、続行する前に検索結果から変数が選択されていることを確認してください。
[Subject] に「カート内の商品をお忘れではありませんか?」と入力します。
[Body Format] で [HTML] を選択します。
[Body in HTML] で [Variable] をクリックします。「customer_message」と入力し、検索結果からその変数を選択します。
赤色の警告が表示された場合は、続行する前に検索結果から変数が選択されていることを確認してください。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
前のタスクでは、BigQuery ML リモートモデルや Pub/Sub の Application Integration トリガーなど、統合に必要なさまざまなコンポーネントを作成して構成しました。
このタスクでは、ワークフローの最後の部分、つまり、放棄されたショッピング カートのレコードを保存する BigQuery テーブルをモニタリングし、対象の顧客に合わせてプロモーション メールを生成するリクエストを Gemini に送信して、パーソナライズされたメールの内容を Pub/Sub トピックに書き込む継続的クエリを作成します。
Google Cloud コンソールで、ナビゲーション メニュー(
[予約を作成] をクリックします。
[予約名] に「bq-continuous-queries-reservation」と入力します。
[場所] で [
[エディション] で [Enterprise] を選択します。
[最大予約サイズ セレクタ] で、[極小(50 スロット)] を選択します。
[ベースライン スロット数] に「50」と入力します。
[保存] をクリックします。
予約が作成されたら、スロット予約テーブルで bq-continuous-queries-reservation という予約の行を特定します。
[アクション] で [予約のアクション](縦に並んだ 3 つの点)をクリックし、[割り当ての作成] を選択します。
[組織、フォルダ、プロジェクトを選択] で、[参照] をクリックし、次のプロジェクトを選択します。
[ジョブタイプ] で [Continuous] を選択します。
[作成] をクリックします。
bq-continuous-queries-reservation という予約の横にある矢印を展開すると、新しい割り当てを確認できます。これは projects/
BigQuery の左側のメニューで [Studio] をクリックします。
[無題のクエリ] をクリックして、空のクエリ ウィンドウにアクセスします。
継続的クエリを作成するための以下のクエリをコピーして貼り付けます。ただし、まだ [実行] はクリックしないでください。
プロンプトが表示されたら、[確認] をクリックします。
[その他の操作](縦に並んだ 3 つの点)> [その他](歯車アイコン)をもう一度クリックして、[クエリ設定] を選択します。
[継続的クエリ] の [サービス アカウント] で、カスタム サービス アカウント [bq-continuous-query-sa@
[保存] をクリックしてクエリの設定を終了します。
クエリ ウィンドウで [実行] をクリックして、継続的クエリを開始します。
継続的クエリが開始されるまで数分かかることがあります。
クエリ ウィンドウの上部に [Job running continously] というステータスが表示されたら、最後のタスクに進むことができます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
最後のタスクでは、継続的クエリをテストします。そのために、abandoned_carts テーブルにデータを追加して、顧客にパーソナライズされたメールを送信する統合を開始します。
BigQuery で + アイコン([無題のクエリ] の右側にある [SQL クエリ])をクリックして、新しいクエリ ウィンドウを開きます。
放棄されたショッピング カートの詳細をテーブルに挿入するための以下のクエリをコピーして貼り付け、[実行] をクリックします。
必要に応じて、Name を自分の名前に置き換えます。生成されたメールにアクセスする場合は、
以下のクエリに含まれるラボのユーザー名(
[結果] に [このステートメントで、abandoned_carts に 1 個の行が追加されました。] というメッセージが表示されたら、このタスクは完了です。
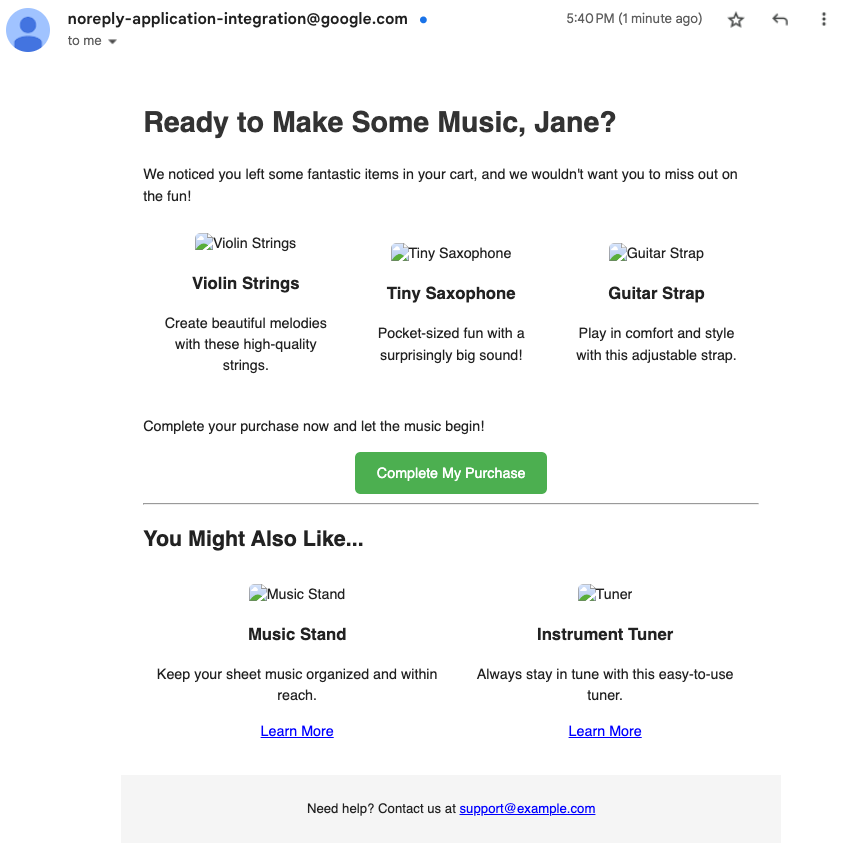
放棄されたカートのテーブルに新しい行を挿入することで、指定のユーザーに放棄されたカート内の商品に関するカスタムメールを送信するワークフローが開始されました。
すぐにアクセスできるメールアドレスを指定した場合は、数分待ってからメールを確認して、放棄されたカートに関するカスタム メッセージを確認します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
このラボでは、BigQuery の継続的クエリ、Gemini 2.0 Flash、Pub/Sub、Application Integration トリガーを使用してパーソナライズされたメールの内容を生成し、送信する方法を学習しました。具体的には、BigQuery の継続的クエリから受信した Pub/Sub メッセージごとにメールを送信するよう Application Integration トリガーを構成しました。この継続的クエリは、顧客に合わせてプロモーション メールを生成するリクエストを Gemini に送信し、パーソナライズされたメールの内容を Pub/Sub トピックに書き込みます。
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2025 年 3 月 25 日
ラボの最終テスト日: 2025 年 3 月 25 日
Copyright 2025 Google LLC. All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください