チェックポイント
Create a dataset
/ 30
Copy a public New York taxi table to your dataset
/ 30
Create a tag template
/ 20
Attach tag to your table
/ 20
Data Catalog: Qwik Start
GSP729

概要
Data Catalog は、Dataplex 内のスケーラブルなフルマネージド型メタデータ管理サービスです。
データ検出のためのシンプルで使いやすい検索インターフェースと、テクニカル メタデータおよびビジネス メタデータの両方を取得できる柔軟で強力なカタログ化システムを提供しています。また、Cloud Data Loss Prevention(DLP)および Cloud Identity and Access Management(IAM)とのインテグレーションにより、セキュリティとコンプライアンスの強固な基盤を備えています。
BigQuery は、Google のインフラストラクチャの処理能力を利用して SQL クエリを高速で実行するエンタープライズ データ ウェアハウスです。
ユーザーがデータを BigQuery に読み込んだら、後の処理は Google 側で行われます。 他のユーザーにデータの表示やクエリを許可するなど、ビジネスニーズに基づいてプロジェクトとデータへのアクセスを制御できます。
Data Catalog の使用
Data Catalog では、主に 2 つの操作を行います。
- アクセス可能なデータアセットを検索する。
- メタデータでアセットにタグ付けする。
Data Catalog のユースケース
自分が自社のデータ エンジニアであると想像してみてください。データ サイエンティストやビジネス アナリストなど、同僚があらゆるデータセットを簡単に探索して使用できるようにすることが仕事です。新しいデータセットを入手したら、重要な情報でアノテーションを付けます。例えば、PII データが含まれているかどうかや、データセットの所有者は誰か、データセットに含まれている行の数はいくつか、といった情報が含まれます。
こういった情報をアノテーションとして付けるには、対象のデータセットとテーブルにタグを追加します。Data Catalog を使用すると、タグ テンプレートを作成して、タグ付けしたい属性の種類を定義できます。これにより、データセットとテーブルに簡単にアクセスしてマッピングし、関連情報を見つけ出すことができます。
ラボの内容
このラボでは、次の方法について学びます。
- Data Catalog API を有効にして、このサービスを Google Cloud プロジェクトで使用できるようにする。
- BigQuery でデータセットを作成する。
- New York Taxi 一般公開テーブルをデータセットにコピーする。
- Data Catalog タグ テンプレートを作成する。
- 新しく作成したテーブルに、新しく作成したタグを付ける。
前提条件
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン
をクリックします。
接続した時点で認証が完了しており、プロジェクトに各自の PROJECT_ID が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
-
[承認] をクリックします。
-
出力は次のようになります。
出力:
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
出力:
出力例:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. Data Catalog API を有効にする
-
ナビゲーション メニューで [API とサービス] > [ライブラリ] を選択します。
-
検索バーに「
Data Catalog」と入力し、1 番目の結果を選択します。 -
続いて [有効にする] をクリックします。
Data Catalog API を有効にしようとして次のエラーが発生した場合:
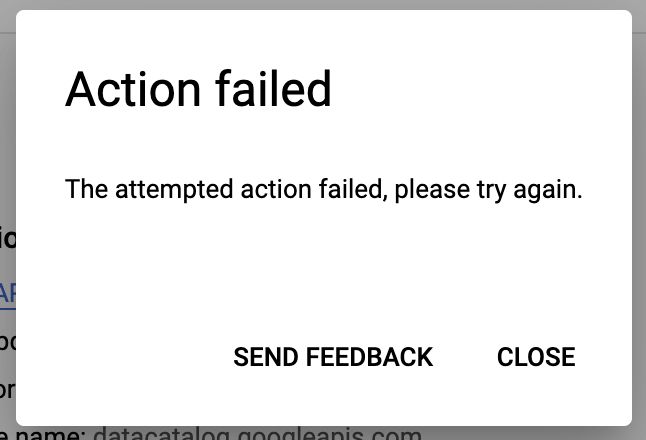
- [閉じる] をクリックします。
- ブラウザのタブを更新します。
- もう一度 [有効にする] をクリックします。
Data Catalog API が正常に有効になるはずです。
BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
- [完了] をクリックします。
BigQuery コンソールが開きます。
タスク 2. データセットを作成する
- BigQuery の左側のナビゲーション パネルで、プロジェクト ID の横に表示される「アクションを表示」アイコンをクリックし、続いて [データセットを作成] をクリックします。
![[アクションを表示] ナビゲーション メニュー。プロジェクトのサブメニュー内で [データセットを作成] オプションがハイライト表示されている。](https://cdn.qwiklabs.com/h%2FSFGiZwxeQZJFlzxwDWhaKRRF%2FsHHxJctZNL%2FMkzN4%3D)
- [データセットを作成する] ダイアログで、次の操作を行います。
-
[データセット ID] に「
demo_dataset」と入力します。 -
[データのロケーション] で、[
us(米国の複数のリージョン)] を選択します。
![[データセットの作成] ページ。[プロジェクト ID]、[データセット ID]、データ ロケーションの各欄が入力されている。](https://cdn.qwiklabs.com/Gt%2B%2F9TWTxPysVENSPBtBzfdn%2B%2FUo3x2mQLiwkJvhF5w%3D)
- [データセットを作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 3. New York Taxi 一般公開テーブルをデータセットにコピーする
-
左側のパネルで、[+ 追加] > [公開データセット] をクリックします。
-
検索バーに「NYC TLC Trips」と入力し、表示される結果をクリックします。
![検索結果。[フィルタ条件] メニューの横にある「NYC TLC Trips」タイルがハイライト表示されている。](https://cdn.qwiklabs.com/DYybiqAWFQP%2F8arU0nQDOzmRH4CBeS%2B3Tx%2B4wc27Tw0%3D)
このラボでは、このデータセットのテーブルを使用します。これには 2018 年のニューヨーク市のタクシー賃走データが含まれています。
-
先に進む準備ができたら、サイドパネルの外をクリックし、コンソールに戻ります。
-
Cloud Shell パネルで次のコマンドを実行して、
tlc_yellow_trips_2018テーブルをコピーします。
上記のコマンドは、bq コマンドライン ツールを使用して一般公開テーブルをプロジェクトにコピーし、先ほど作成した demo_dataset に配置しました。
-
BigQueryブラウザページを更新します。
-
trips テーブルが
demo_datasetにリストされていることを確認します。
次のセクションでは、このテーブルに Data Catalog タグを追加します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 4. Data Catalog タグ テンプレートを作成する
Data Catalog UI でタグ テンプレートを作成します。
- ナビゲーション メニューを開き、[Data Catalog] > [タグ テンプレート] を開きます。[+ タグ テンプレートを作成] をクリックします。
![[Data Catalog] ペイン。[テンプレートの作成] ボタンとともにタグ テンプレート オプションがハイライト表示されている。](https://cdn.qwiklabs.com/RVHPadp9kRinQa2CE%2FP%2FrKXGh1VeRL%2BkT00IkxkcxA0%3D)
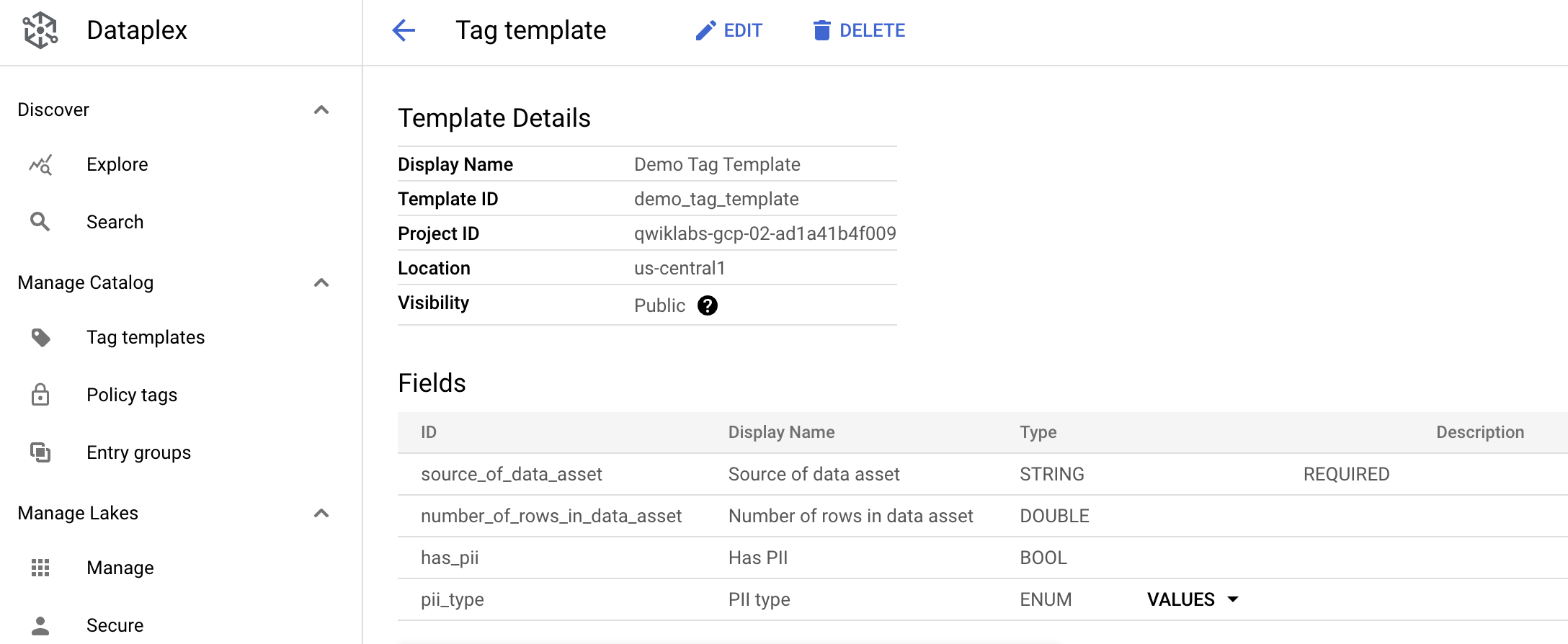
- テンプレート フォームに入力して、「Demo Tag Template」を定義します。
- テンプレートの表示名: Demo Tag Template
- テンプレート ID: demo_tag_template
-
ロケーション:
次に、4 つのタグ属性(タグ「フィールド」とも呼ばれます)を作成します。
- [フィールドを追加] をクリックします。
下記の値を持つ 4 つの属性を作成します。「ソース」属性は必須タグ属性を定義します。属性名には小文字とアンダースコアを使用できます。
- フィールド表示名: Source of data asset
- フィールド ID: source_of_data_asset
- このフィールドを必須にする: オン
- タイプ: 文字列
-
[完了] をクリックします。
-
[フィールドを追加] をクリックして、以下のように入力します。
- フィールド表示名: Number of rows in data asset
- フィールド ID: number_of_rows_in_data_asset
- このフィールドを必須にする: オフ
- タイプ: 倍精度
-
[完了] をクリックします。
-
[フィールドを追加] をクリックして、以下のように入力します。
- フィールド表示名: Has PII
- フィールド ID: has_pii
- このフィールドを必須にする: オフ
- タイプ: ブール値
-
[完了] をクリックします。
-
[フィールドを追加] をクリックして、以下のように入力します。
- フィールド表示名: PII type
- フィールド ID: pii_type
- このフィールドを必須にする: オフ
- タイプ: 列挙
- この属性には次の 3 つの値を追加します。
- Social Security Number
- なし
- 次に [完了] をクリックします。
完成したタグ テンプレート フォームには、次の 4 つのタグ属性がリストされます。
![完成したタグ テンプレート フォーム、[公開設定] オプション、[作成] ボタン、[キャンセル] ボタン。](https://cdn.qwiklabs.com/v%2BkPm3vPxDnlQQBbgV7fO82BH2JJlwP39yLg%2Feg%2BLC0%3D)
- [作成] をクリックします。
Data Catalog の [タグ テンプレート] ページには、テンプレートの詳細と属性が表示されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 5. 新しく作成したタグをテーブルに追加する
-
データアセット内のテーブルにタグを付けるには、左上にある Data Catalog アイコンをクリックします。
-
左側のペインにある [検索] をクリックし、検索ボックスに「
demo_dataset」と入力します。 -
[検索] をクリックします。

先ほどデータセットにコピーした demo_dataset と trips テーブルが検索結果に表示されます。
- 「trips」をクリックしてテーブルを開きます。
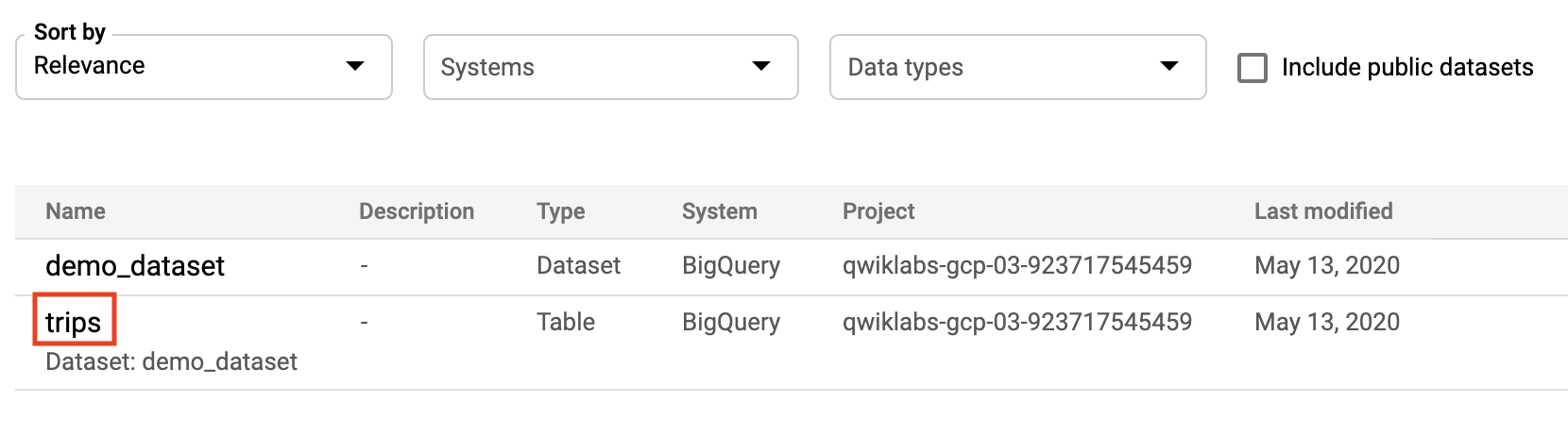
[エンティティの詳細] ページが開きます。
- [タグを付ける] をクリックします。
![[エンティティの詳細] ページ。[タグを付ける] ボタンがハイライト表示されている。](https://cdn.qwiklabs.com/vxzVzlZq3NWjuY8ys3o9%2B99IyiEi2QDll32jgCdwy3M%3D)
-
[タグを付ける] ダイアログの「タグを付ける対象の選択」の下で
tripsテーブルを選択し、[OK] をクリックします。 -
タグ テンプレートに「Demo Tag Template」を選択します。
-
次に、タグの各属性に次の値を挿入または選択します。
- Source of data asset: tlc_yellow_trips_2018
- PII type: NONE
![[タグを付ける] ページ。Demo Tag Template 内では、[Source of data asset] と [PII type] が選択され、値が入力されている。](https://cdn.qwiklabs.com/gbErK282NkxCfhH3AIO5JDf878vJ6LFDVufNWbTQQ7w%3D)
-
[保存] をクリックします。
-
「
Demo Tag Template」をクリックすると、タグ属性が [エンティティの詳細] ページに表示されます。
![[エンティティの詳細] ページ。Demo Tag Template の表示名、データアセットのソース、および PII タイプが表示されている。](https://cdn.qwiklabs.com/2X3nOUKYH%2Fq14Tx2xKP5A5S7bT3KBOTQmnATZCMDb0I%3D)
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
お疲れさまでした
お疲れさまでした。Data Catalog を使用して、タグをテーブルに正しく付ける方法を学習しました。
クエストを完了する
このセルフペース ラボは、「BigQuery for Marketing Analysts」クエストと「Data Catalog Fundamentals」クエストの一部です。クエストとは学習プログラムを構成する一連のラボのことで、完了すると成果が認められて上のようなバッジが贈られます。バッジは公開して、オンライン レジュメやソーシャル メディア アカウントにリンクできます。このラボの修了後、このラボが含まれるクエストに登録すれば、すぐにクレジットを受け取ることができます。受講可能なすべてのクエストについては、Google Cloud Skills Boost カタログをご覧ください。
学習した内容
このラボでは、以下の操作について学習しました。
- Data Catalog API の有効化
- データセットの作成
- データセットへの New York Taxi 一般公開テーブルのコピー
- タグ テンプレートの作成とテーブルへのタグ添付
次のステップと詳細情報
ラボを終了する
ラボが完了したら、[ラボを終了] をクリックします。ラボのプラットフォームから、アカウントと使用したリソースが削除されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
- 星 1 つ = 非常に不満
- 星 2 つ = 不満
- 星 3 つ = どちらともいえない
- 星 4 つ = 満足
- 星 5 つ = 非常に満足
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 9 月 20 日
ラボの最終テスト日: 2023 年 9 月 20 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。