





始める前に
- ラボでは、Google Cloud プロジェクトとリソースを一定の時間利用します
- ラボには時間制限があり、一時停止機能はありません。ラボを終了した場合は、最初からやり直す必要があります。
- 画面左上の [ラボを開始] をクリックして開始します
このラボでは、ニューヨーク市のタクシー車両を多数所有しているものと仮定して、リアルタイムでビジネスの状況をモニタリングします。タクシーの収益、乗客数、乗車状況などを把握し、その結果を管理ダッシュボードで視覚化するためのストリーミング データ パイプラインを構築します。
このラボでは、次の方法について学びます。
各ラボでは、新しい Google Cloud プロジェクトとリソースセットを一定時間無料で利用できます。
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウで開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
[ラボの詳細] パネルでもユーザー名を確認できます。
[次へ] をクリックします。
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
[ラボの詳細] パネルでもパスワードを確認できます。
[次へ] をクリックします。
その後次のように進みます。
その後、このタブで Google Cloud コンソールが開きます。

Google Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。
Google Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
Google Cloud コンソールで、右上のツールバーにある [Cloud Shell をアクティブにする] ボタンをクリックします。
[続行] をクリックします。
環境がプロビジョニングされ、接続されるまでしばらく待ちます。接続した時点で認証が完了しており、プロジェクトに各自のプロジェクト ID が設定されます。次に例を示します。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
出力:
出力例:
出力:
出力例:
このタスクでは、taxirides データセットを作成します。Google Cloud Shell か Google Cloud コンソールを使用してこのデータセットを作成できます。
このラボでは、NYC Taxi & Limousine Commission の公開データセットの抜粋を使用します。小さなカンマ区切りのデータファイルは、タクシーに関するデータの定期的な更新をシミュレートするために使用されます。
BigQuery はサーバーレス データ ウェアハウスです。BigQuery 内のテーブルは、データセットに編成されます。このラボでは、タクシーに関するデータがスタンドアロン ファイルから Dataflow 経由で流れ、BigQuery に保存されます。この設定では、ソースの Cloud Storage バケットに付与された新しいデータファイルはすべて、読み込み用に自動処理されます。
次のいずれかの方法で新しい BigQuery データセットを作成します。
 )で、次のコマンドを実行して
)で、次のコマンドを実行して taxirides データセットを作成します。taxirides.realtime テーブルを作成します(この空のスキーマに後でデータをストリーミングします)。Google Cloud コンソールのナビゲーション メニュー(
ようこそのダイアログが表示されたら、[完了] をクリックします。
プロジェクト ID の横に表示される [アクションを表示] (
[データセット ID] に「taxirides」と入力します。
データのロケーション で以下を選択します。
次に、[データセットを作成] をクリックします。
[エクスプローラ] ペインで [ノードを展開します](
taxirides データセットの横の アクションを表示(
[テーブルを作成] をクリックします。
[テーブル] に「realtime」と入力します。
[スキーマ] で [テキストとして編集] をクリックし、以下のスキーマを貼り付けます。
[パーティションとクラスタの設定] で [タイムスタンプ] を選択します。
[テーブルを作成] をクリックします。
このタスクでは、必要なファイルをプロジェクトに移動します。
Cloud Storage では、世界中のどこからでも、いつでもデータを保存、取得できます。データの量に制限はありません。ウェブサイト コンテンツの提供、アーカイブと障害復旧のためのデータの保存、直接ダウンロードによるユーザーへの大きなデータ オブジェクトの配布など、さまざまなシナリオで Cloud Storage を使用できます。
Cloud Storage バケットは、ラボの開始時に作成されています。
)で、次のコマンドを実行して Dataflow ジョブに必要なファイルを移動します。このタスクでは、Cloud Storage バケットからファイルを読み取り、BigQuery にデータを書き込むストリーミング データ パイプラインを設定します。
Dataflow では、サーバーレスでデータ分析を行うことができます。
Cloud コンソールのナビゲーション メニュー(
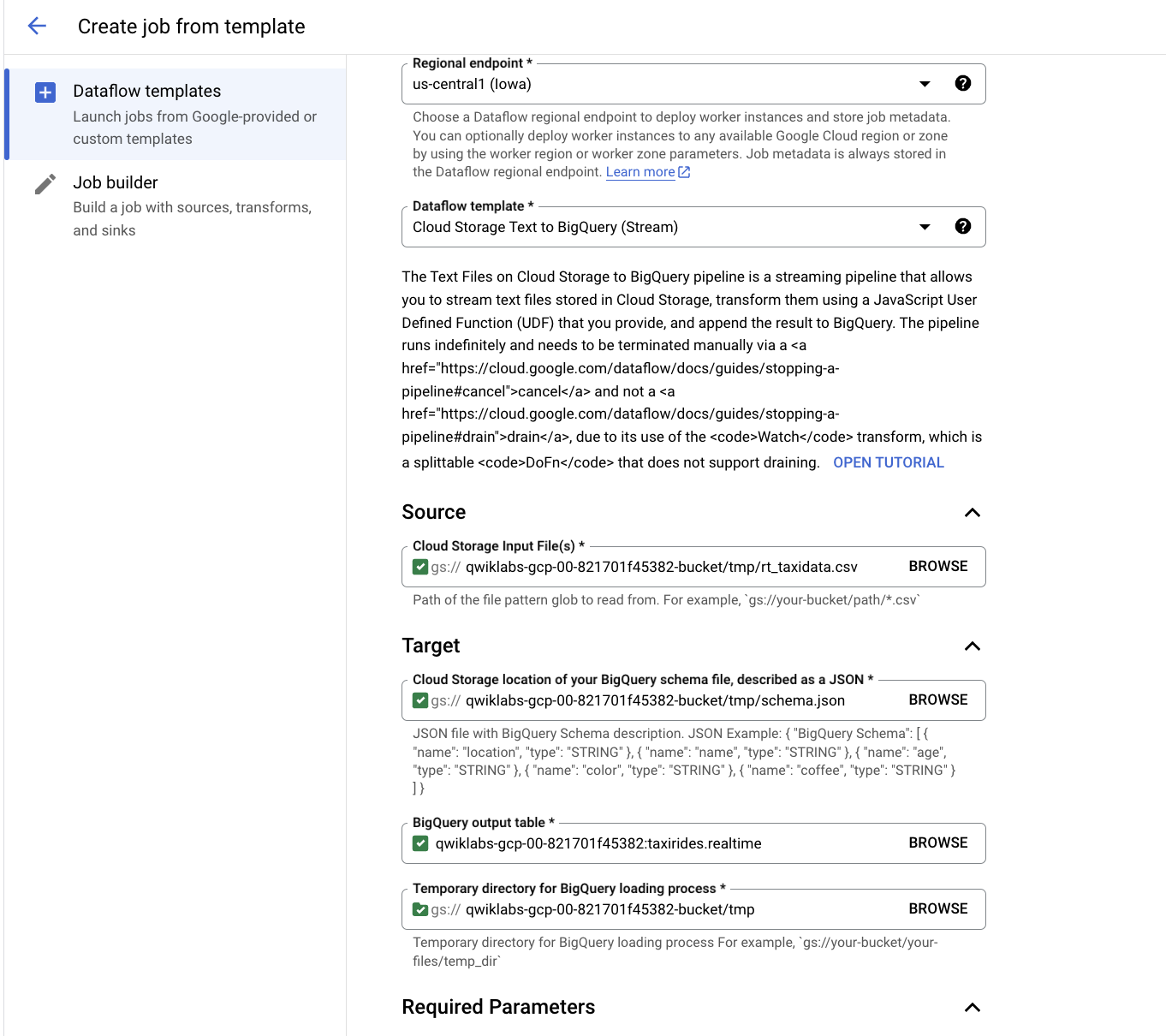
上部のメニューバーの [テンプレートからジョブを作成] をクリックします。
Dataflow ジョブのジョブ名として「streaming-taxi-pipeline」と入力します。
[リージョン エンドポイント] で、以下を選択します。
[必須パラメータ] をクリックします。
一時ファイルの書き込みに使用する [一時的な場所] に、以下のコマンドを貼り付けるか入力します。
[最大ワーカー数] に「2」と入力します。
[ワーカーの数] に「1」と入力します。
[デフォルトのマシンタイプを使用する] チェックボックスをオフにします。
[汎用] で次の設定を選択します。
シリーズ: E2
マシンタイプ: e2-medium(2 個の vCPU、4 GB メモリ)
新しいストリーミング ジョブが開始されます。これで、データ パイプラインを視覚的に表示できるようになりました。BigQuery へのデータ移行が開始されるまで 3~5 分かかります。
このタスクでは、ストリーミング中のデータを分析します。
Google Cloud コンソールのナビゲーション メニュー(
ようこそのダイアログが表示されたら、[完了] をクリックします。
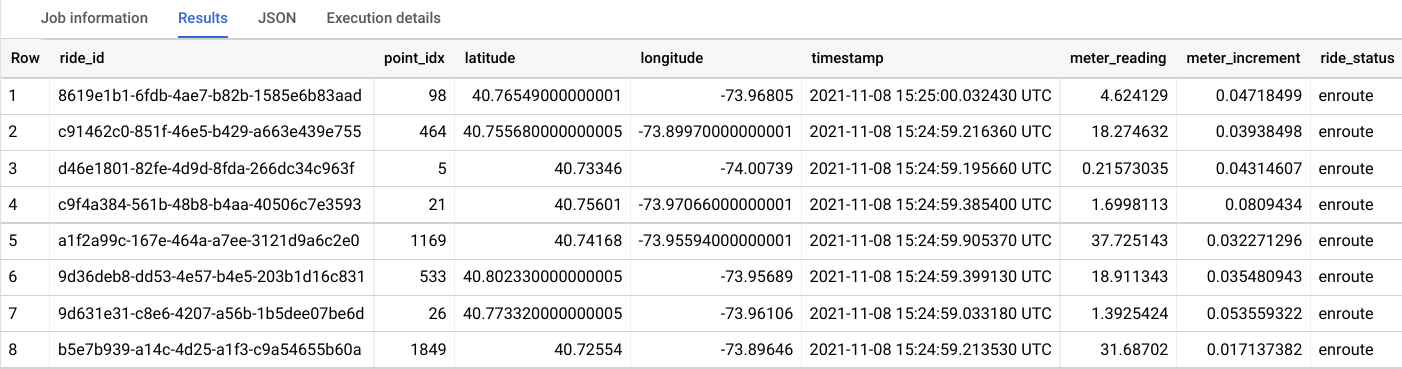
クエリエディタに次のクエリを入力して、[実行] をクリックします。
出力は次のようになります。
このタスクでは、レポート用にストリームの集計を行います。
クエリエディタで現在のクエリを削除します。
以下のクエリをコピーして貼り付け、[実行] をクリックします。
結果には、タクシーの降車ごとの主な指標が分単位で表示されます。
[保存] > [クエリを保存] をクリックします。
[クエリを保存] ダイアログの [名前] フィールドに「My Saved Query」と入力します。
[リージョン] で、リージョンが Qwiklabs ラボのリージョンと一致していることを確認します。
[保存] をクリックします。
このタスクでは、Dataflow ジョブを停止して、プロジェクト用のリソースを開放します。
Cloud コンソールのナビゲーション メニュー(
[streaming-taxi-pipeline] または新しいジョブ名をクリックします。
[停止] をクリックし、[キャンセル] > [ジョブの停止] を選択します。
このタスクでは、リアルタイム ダッシュボードを作成して、データを可視化します。
Google Cloud コンソールのナビゲーション メニュー(
[エクスプローラ] ペインでプロジェクト ID を展開します。
[クエリ] を展開し、[My Saved Query] をクリックします。
クエリがクエリエディタに読み込まれます。
[実行] をクリックします。
[クエリ結果] セクションで、[次で開く] > [Looker Studio] をクリックします。
Looker Studio が開きます。[Get started] をクリックします。
Looker Studio ウィンドウで棒グラフをクリックします。
(
[グラフ] ペインが表示されます。
[グラフを追加] をクリックし、[複合グラフ] を選択します。
[設定] ペインの [期間のディメンション] で、[minute (Date)] にカーソルを合わせて [X] をクリックして削除します。
[データ] ペインで、[dashboard_sort] をクリックして、[設定] > [期間のディメンション] > [ディメンションを追加] にドラッグします。
[設定] > [ディメンション] で、[分] をクリックし、[dashboard_sort] を選択します。
[設定] > [指標] で、[dashboard_sort] をクリックし、[total_rides] を選択します。
[設定] > [指標] で、[Record Count] をクリックし、[total_passengers] を選択します。
[設定] > [指標] で、[指標を追加] をクリックし、[total_revenue] を選択します。
[設定] > [並べ替え] で、[total_rides] をクリックし、[dashboard_sort] を選択します。
[設定] > [並べ替え] で、[昇順] をクリックします。
グラフの表示は次のようになります。
ダッシュボードに問題がなければ、[保存して共有] をクリックしてこのデータソースを保存します。
アカウント設定を完了するダイアログが表示されたら、国と会社の詳細を入力し、利用規約に同意してから [続行] をクリックします。
どの更新情報を受け取るかを答えるように求められたら、すべて「いいえ」で回答して [続行] をクリックします。
[データアクセスを確認してから保存] ウィンドウが表示されたら、[同意して保存する] をクリックします。
アカウントを選択するよう求められたら、[Student Account] を選択します。
ダッシュボードにいつ誰がアクセスしても、最新のトランザクションが表示されます。その他のオプション(
このタスクでは、期間グラフを作成します。
こちらの Looker Studio リンクをクリックして、新しいブラウザタブで Looker Studio を開きます。
[レポート] ページの [テンプレートを使って開始] で、[[+] 空のレポート] テンプレートをクリックします。
新しい空白のレポートと [データのレポートへの追加] ウィンドウが表示されます。
[Google Connectors] のリストから、[BigQuery] タイルを選択します。
[カスタムクエリ] をクリックして、プロジェクト ID を選択します。これは qwiklabs-gcp-xxxxxxx の形式で表示されます。
[カスタムクエリを入力] に以下のクエリを貼り付けます。
[追加] > [レポートに追加] をクリックします。
無題の新しいレポートが表示されます。画面の更新には最長で 1 分かかる場合があります。
[データ] ペインで、[フィールドを追加] > [計算フィールドを追加] をクリックします。
左隅で [すべてのフィールド] をクリックします。
[タイムスタンプ] フィールドのタイプを [日付と時刻] > [日付、時、分(YYYYMMDDhhmm)] に変更します。
タイムスタンプの変更ダイアログで、[続行] をクリックし、[完了] をクリックします。
トップメニューで [グラフを追加] をクリックします。
[期間グラフ] を選択します。
グラフをページ左下隅の何もない場所に配置します。
[設定] > [ディメンション] で、[timestamp (Date)] をクリックし、[timestamp] を選択します。
[設定] > [ディメンション] で、[timestamp] をクリックし、[calendar] を選択します。
[データタイプ] で、[日付と時刻] > [日付、時、分] を選択します。
ダイアログの外側をクリックして閉じます。名前を追加する必要はありません。
[設定] > [指標] で、[Record Count] をクリックし、[meter reading] を選択します。
このラボでは、Dataflow を使用して、パイプライン経由で BigQuery にデータをストリーミングしました。
ラボが完了したら、[ラボを終了] をクリックします。ラボで使用したリソースが Google Cloud Skills Boost から削除され、アカウントの情報も消去されます。
ラボの評価を求めるダイアログが表示されたら、星の数を選択してコメントを入力し、[送信] をクリックします。
星の数は、それぞれ次の評価を表します。
フィードバックを送信しない場合は、ダイアログ ボックスを閉じてください。
フィードバックやご提案の送信、修正が必要な箇所をご報告いただく際は、[サポート] タブをご利用ください。
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは、Google LLC の商標です。その他すべての社名および製品名は、それぞれ該当する企業の商標である可能性があります。



このコンテンツは現在ご利用いただけません
利用可能になりましたら、メールでお知らせいたします

ありがとうございます。
利用可能になりましたら、メールでご連絡いたします

1 回に 1 つのラボ
既存のラボをすべて終了して、このラボを開始することを確認してください