Checkpoints
Creating a log sink
/ 20
Deploying the Pub/Sub to Splunk Dataflow Template
/ 30
Create a Service Account for Splunk TA
/ 30
Bonus - Pub/Sub Input
/ 10
Monitor and troubleshoot pipelines
/ 10
Getting Started with Splunk Cloud GDI on Google Cloud
- GSP947
- Overview
- Setup a Splunk trial account
- Task 1. Install the Splunk Add-on for Google Cloud
- Task 2. Create HECs
- Task 3. Setting environment variables
- Task 4. Creating a log sink
- Task 5. Deploying the Pub/Sub to Splunk Dataflow Template
- Task 6. Configure the Splunk TA for Google Cloud
- Task 7. Sample searches
- Task 8. Monitor and troubleshoot pipelines
- Task 9. Comparison of methods
- Task 10. (Optional) Online Boutique Demo
- Congratulations!
This lab was developed with our partner, Splunk. Your personal information may be shared with Splunk, the lab sponsor, if you have opted in to receive product updates, announcements, and offers in your Account Profile.
GSP947

Overview
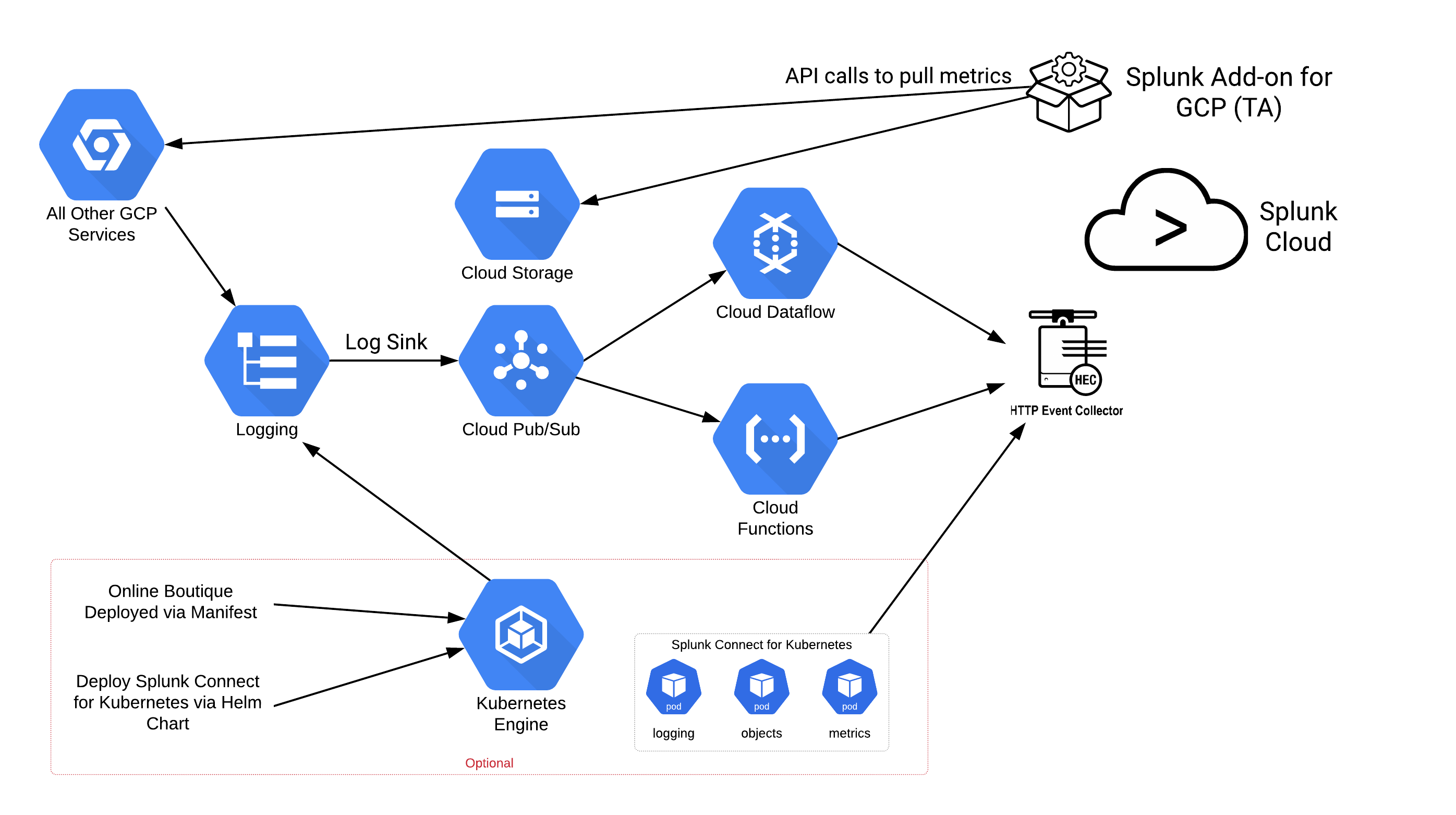
In this hands-on lab, you'll learn how to configure Google Cloud to send logging and other infrastructure data to Splunk Cloud via Dataflow, the Splunk Add-on for Google Cloud Platform, and Splunk Connect for Kubernetes (SC4K).
Although you can easily copy and paste commands from the lab to the appropriate place, students should type the commands themselves to reinforce their understanding of the core concepts.
Objectives
In this lab, you will:
- Create a Splunk Cloud trial.
- Install the Splunk Add-on for Google Cloud Platform (GCP-TA).
- Create Splunk indexes.
- Create Splunk HTTP Event Collectors (HECs).
- Create log sinks.
- Create Cloud Storage buckets.
- Create Pub/Sub topics and subscriptions.
- Launch a Dataflow template deployment.
- Configure GCP-TA inputs.
- Perform sample Splunk searches across ingested data.
- Monitor and troubleshoot Dataflow pipelines.
- Deploy a demo "Online Boutique" microservice in GKE (optional).
- Install Splunk Connect for Kubernetes (SC4K) (optional).
Prerequisites
- Familiarity with Splunk is beneficial.
Architecture you'll configure
Setup a Splunk trial account
Prior to starting the timer on this lab, please create and configure a Splunk Cloud trial.
-
Visit splunk.com to sign up for a free trial account.
-
Once you have logged into splunk.com, click on "Free Splunk."
-
Then click Get the Free Trial.
-
Then click Start trial.
Credentials for your trial Splunk Cloud environment will be sent to your email. Please check your spam folder if you do not see the email in your inbox. Look for an email with the subject "Cloud Fulfillment". In this email you'll find a custom URL for your instance, your admin username and temporary password. This is not the same password of your Splunk Portal.
Copy that URL you received in the email and open it in a web browser. Log in your instance using the admin username and temporary password. Once you’ve logged into your Splunk Cloud instance, you will be asked to change the password and accept the terms of service. Please do so before proceeding.
Task 1. Install the Splunk Add-on for Google Cloud
Next, install the Splunk Add-on for Google Cloud.
-
On the left pane click on + Find More Apps.
-
Search for "Google Cloud" in the search box.
-
To narrow search results, ensure "IT Operations" and "Business Analytics" are checked under Category.
-
Choose Add-on under App Type, Splunk Supported under Support Type, Inputs under App Content, and Yes under Fedramp.
-
Look for the "Splunk Add-on for Google Cloud Platform" search result under Best Match.
-
Click on the Install button.
You will be required to enter your Splunk.com credentials. This should be the same account you used to initiate the Splunk Cloud trial. This is not the trial instance admin user and password that you just used.
-
Ensure you have placed a check in the box indicating you have reviewed the Splunk software terms and conditions.
-
Click the Agree and Install button to proceed.
Once you have logged in successfully, you will see a screen indicating that the add-on is downloading and installing.
If you encounter an error with your username/password ensure that you have verified your e-mail address (a confirmation is sent via e-mail to confirm the address).
Finally, you will see a screen indicating the installation is complete.
- Click Done.
You may see a warning in the "Messages" dropdown section of the top navigation bar indicating that Splunk must be restarted. For the purposes of this lab, you can safely ignore this message.
Create indexes
An index is a repository for Splunk data. Splunk Cloud transforms incoming data into events which it then persists to an index.
You will need to create the following event indexes for this lab:
- gcp_data - For data from Splunk Dataflow template
- gcp_ta - For data from the Splunk Add-on for Google Cloud
- gcp_connect - For data from Splunk Connect for Kubernetes (SC4K)
You will need to create the following metric indexes for this lab:
- gcp_metrics - For metric data from Splunk Connect for Kubernetes (SC4K)
- To create an index, click on the Apps dropdown menu in the top left navigation bar. Select the "Search and Reporting" app.
If this is the first time you're opening this app, click Skip tour in the bottom right corner.
-
Next, click on Settings.
-
Once this menu is expanded, click Indexes.
-
Click New Index.
-
Use "Index name" as gcp_data and leave "Index Data Type" set as Events.
-
Set "Max raw data size" to 0 and "Searchable retention (days)" to 15.
-
Click Save to create the index.
-
Following the same aforementioned gcp_data steps above, create the other gcp_ta, and gcp_connect indexes. Use the same type, size, and searchable time.
-
You will also need to create a metrics index for gcp_metrics. The steps are the same as previous indexes, with the exception of selecting a "Metrics" index rather than an "Events" index during creation.
Task 2. Create HECs
The HTTP Event Collector (HEC) is a fast and efficient way to send data over HTTP (or HTTPS) to Splunk Cloud from a logging source such as Splunk Connect for Kubernetes (SC4K) or the Splunk Dataflow template. In this section, you will create HEC endpoints along with corresponding authentication tokens.
SC4K HEC
-
Click Settings > Data Inputs in the Splunk Cloud top navigation.
-
Click on Add New next to HTTP Event Collector.
-
Name the HEC gcp-sc4k and leave other fields as default.
-
Click Next.
-
In the "Selected Allow Indexes" chooser, select the gcp_connect and gcp_metrics indexes created in the previous step.
-
Select the gcp_connect index as the default index.
-
Review and submit the HEC configuration.
-
Copy the token value to a temporary scratch file. You will be using this token later in the lab.
Dataflow HEC
-
Click Settings > Data Inputs in the Splunk Cloud top navigation.
-
Click on Add New next to HTTP Event Collector.
-
Name the HEC gcp-dataflow and leave other fields as default.
-
Click Next.
-
In the "Source type" section, click Select and specify google:gcp:pubsub:message as the source type.
-
In the "Selected Allow Indexes" chooser, select the gcp_data index.
-
Select the gcp_data index as the default index.
-
Review and submit the HEC configuration.
-
Copy the token value to a temporary scratch file. You will be using this token later in the lab.
Open Cloud Shell
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
- Click Activate Cloud Shell
at the top of the Google Cloud console.
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
- Click Authorize.
Output:
- (Optional) You can list the project ID with this command:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
Task 3. Setting environment variables
CLI
This section is only required if you're performing lab steps via the CLI.
-
Launch Cloud Shell.
-
Ensure the Project ID variables is set:
If the environment variable is not set, please follow the steps above under "Google Cloud Shell".
- Set the environment variables.
First, assign several Splunk Cloud-specific environment variables. You will need to supply the hostname of your Splunk Cloud instance along with the HEC tokens you created in the previous HTTP Event Collector setup steps:
For example:
Additionally, please set the following environment variables:
Task 4. Creating a log sink
The first step to getting data from Operations Logging (Stackdriver) to Splunk is to create a log sink. All logging data for Google Cloud is sent to Operations Logging; the sink exports that data real-time to another location (Pub/Sub, BigQuery, Cloud Storage). You will forward the logs on to Pub/Sub for processing.
You have to be careful that you don't create an infinite loop of logging. If you don't have exclusions on the log sink then the system will attempt to send the log event of it sending a previous event which creates another log event that it will then try to forward.
This process also creates the destination Pub/Sub topic (automatically in the UI, manually via the CLI).
Cloud Console
-
In the Cloud Console go to Analytics > Pub/Sub > Topics.
-
Click on Create Topic.
-
Name the sink
splunk-dataflow-sink, leave the default values, and click Create. -
Next, in the Cloud Console go to Operations > Logging > Log Router.
- Click on Create Sink.
- Name the sink
splunk-dataflow-sinkand click Next.
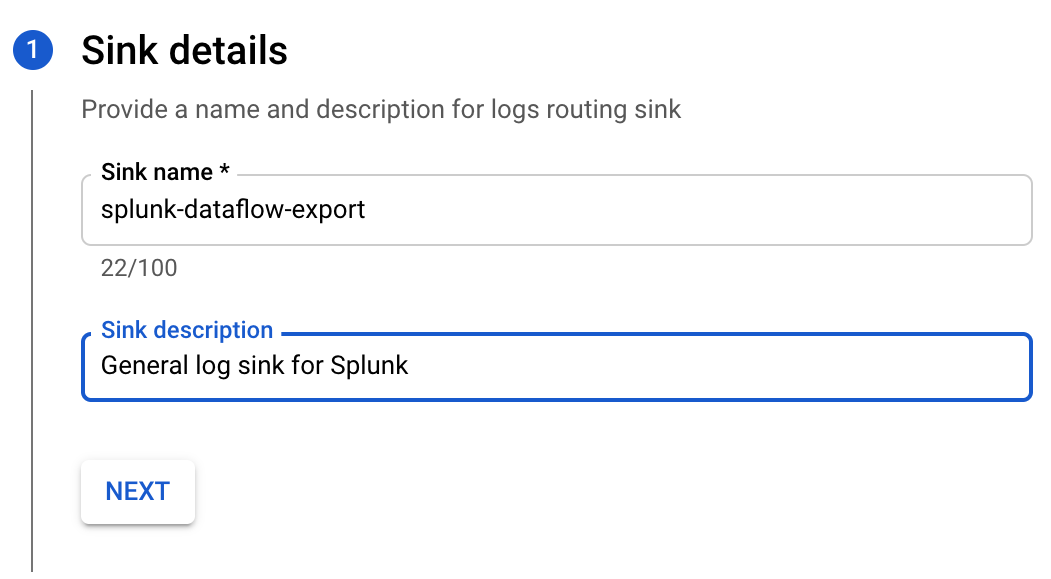
- Specify Splunk as the sink service and select the topic that you created above then click Next.
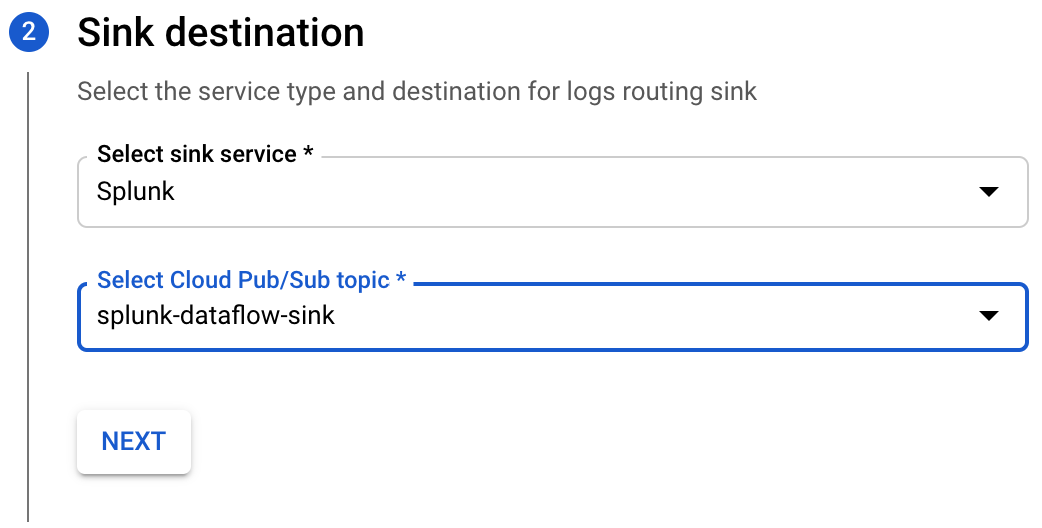
- Leave the inclusion filter blank in order to send all logs to Splunk unless excluded, then click Next.
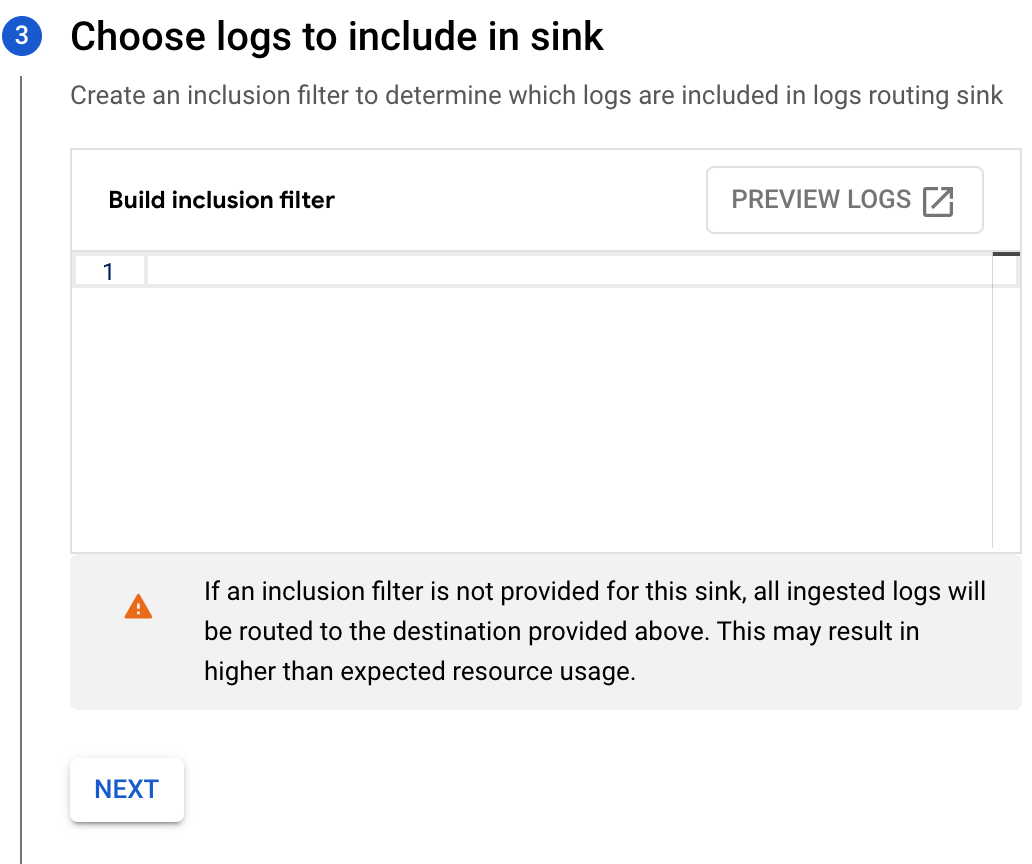
- Click Add Exclusion to specify an exclusion filter to omit Dataflow logs.
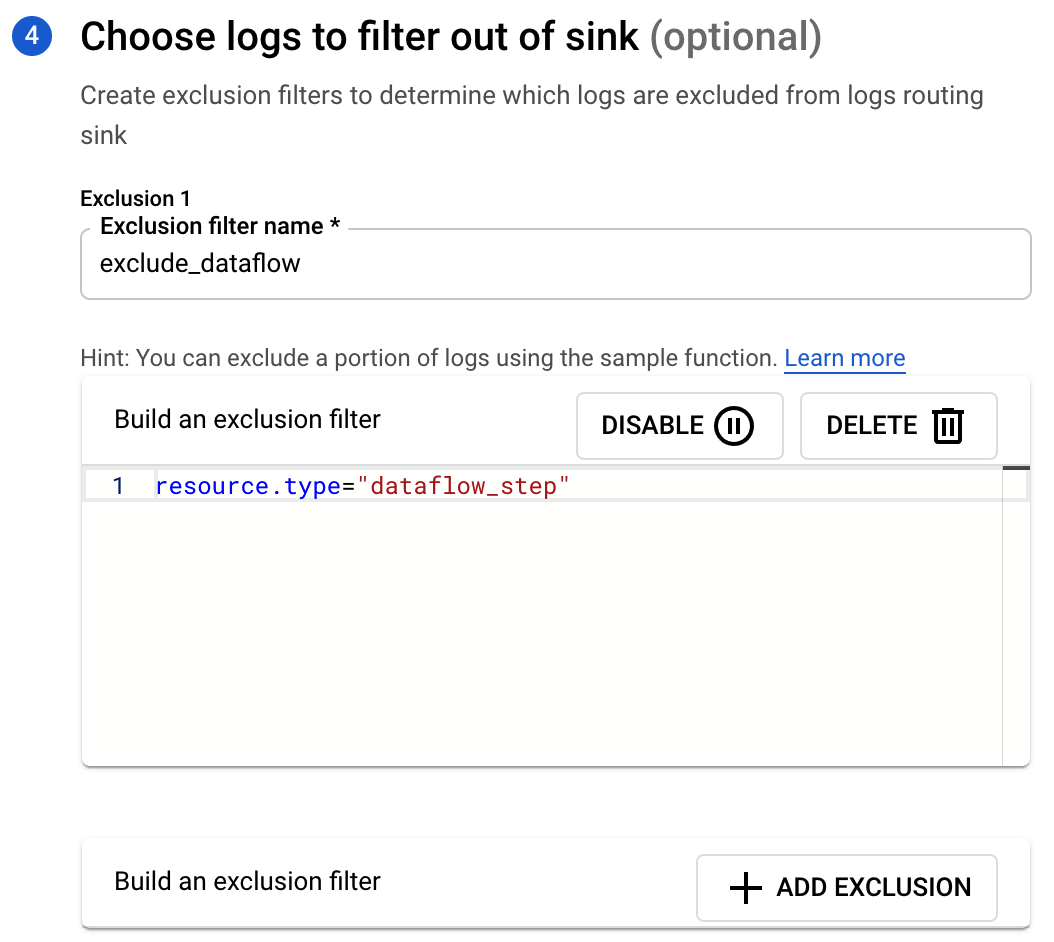
- Once complete click on Create Sink.
CLI
- In Cloud Shell (with the environment variables set), create the Pub/Sub topic:
- Create the log sink:
- Set the environment variable for the correct service account:
- Modify the IAM permissions of Pub/Sub topic to allow the log sink to publish:
Click Check my progress to verify the objective.
Task 5. Deploying the Pub/Sub to Splunk Dataflow Template
The next part of getting the logging sent to Splunk is the deployment of the Pub/Sub to Splunk Dataflow Template. This deploys a Dataflow pipeline that streams the events from a Pub/Sub subscription, batches them up, and sends them to Splunk HEC. Optionally (although not done in the lab), you can add an inline UDF function that manipulates the log messages. This could be a process to remove sensitive information or augment the message with additional data from another source.
The Pub/Sub to Splunk Dataflow template is just one way of sending data to Splunk. In a later section you will also explore using the Splunk Add-on for Google Cloud.
Enable Dataflow Service Account
-
Go to Navigation menu > IAM & Admin > IAM.
-
Click the pencil icon on the
compute@developer.gserviceaccount.comservice account. -
Select the Dataflow Admin role (in the Role dropdown menu) and click Save.
Cloud Console
Now you will create a bucket for the Dataflow template used during deployment.
-
Go to Navigation menu > Cloud Storage > Buckets.
-
Click on + Create.
- Give your bucket a globally unique name (
<project-id>-dataflowwould be unique). - Select
Regionfor Location type and choose ‘<ql-variable key="project_0.default_region" placeHolder="<filled in at lab start>"></ql-variable>' for the Location. - Click on Create (leaving the rest of the options as default). If you see a pop-up window named "Public access will be prevented", click Confirm.
Now you will create a Pub/Sub Topic for the dead letter queue.
- Go to Navigation Menu > Analytics > Pub/Sub > Topics.
You'll see the one topic created for the logs router.
- Click Create Topic to create another.
- Type
splunk-dataflow-deadletterfor Topic ID. - Leave the default values and click Create Topic.
You'll be forwarded to the topic page for the dead letter queue.
-
Scroll down to subscriptions.
-
Click on Create Subscription > Create Subscription to create a subscription to store items forwarded to the dead letter queue. If a topic doesn't have a subscription anything sent to it is discarded.
-
Type
deadletterin the Subscription ID field and leave all else as default. -
Click Create.
Note: The "enable dead lettering" option on the subscription creation page is used when the subscription (usually a push) fails to send the message to its target. This is not to be confused with the dead letter Pub/Sub topic you created for Dataflow, which is used in the scenario where the Dataflow template is unable to send the data to Splunk HEC. Therefore the "enable dead lettering" option here can be ignored. The Dataflow pipeline to Splunk has built-in capability to handle message retries.
- Create the Pub/Sub subscription for Dataflow to process logs. While the log sink step created the topic to dump the logs into you have to create a subscription to that topic so that the message in that topic are delivered to Dataflow.
- Click on Topics on the right-hand menu, then click on the initial Pub/Sub topic created (
splunk-dataflow-sink) by the Log Router. - Scroll down on the topic page.
- Click on Create Subscription as you did for the dead letter topic.
- Type
dataflowfor Subscription ID and create the subscription for Dataflow (leave all other defaults). - Click Create.
- Click on the newly created subscription and note down the subscription name as you will need it in a later step (format should be
projects/<your-project-id>/subscription/dataflow).
- Next, deploy the Dataflow Template:
- Go to Navigation menu > Analytics > Dataflow > Jobs.
- Click on Create Job from Template.
- Type
splunk-dataflowin the Job name field - Select
as the Regional endpoint. - Select the Pub/Sub to Splunk template in the Dataflow template dropdown menu.
- Enter the main required parameters:
|
Input Cloud Pub/Sub subscription |
projects/<your-project-id>/subscriptions/dataflow |
|
HEC URL |
https://<splunk-cloud-host-name>:8088 |
|
Output deadletter Pub/Sub topic |
projects/<your-project-id>/topics/splunk-dataflow-deadletter |
|
Temporary location |
<your-project-id>-dataflow/tmp |
-
Click on Show Optional Parameters.
-
Set the parameters as shown:
HEC Authentication token
<your-dataflow-hec-token>
Batch size
10
Maximum number of parallel requests
4
Disable SSL certification validation
trueInclude full Pub/Sub message in the payload
trueMax workers
2
Worker region
Use job's regional endpoint
Use default machine type
Unselected
Machine type
e2-medium
- Click on Run Job.
The job should take a few minutes to deploy. Once deployed, you can monitor the job throughput and other metrics using the Job Graph and Job Metrics tabs. For example, you can monitor the throughput metric to track the number of events processed over time.
CLI
- Enable the Dataflow API:
- Create a bucket for the Dataflow template use during deployment:
- Create a Pub/Sub topic for the deadletter queue and a subscription:
- Create the Pub/Sub subscription for Dataflow to process logs:
- Deploy the Dataflow Template:
Click Check my progress to verify the objective.
Task 6. Configure the Splunk TA for Google Cloud
Create a Service Account for Splunk TA
In order to connect the Splunk Add-on for Google Cloud (TA) to Google Cloud to pull data, create a service account with appropriate permissions. In this lab you are providing the service account an exhaustive list of permissions as you are connecting all input methods. If you're using the TA only for a few of the inputs, a reduced list of permissions can be set.
Cloud Console
- Go to Navigation menu > IAM & Admin > Service Accounts.
- Click on + Create Service Account.
-
Type
splunk-tain the Service account name field -
Click Create & Continue.
-
Add the permissions needed (you can search to make it easier to find them):
-
Compute Admin
-
Logs Configuration Writer
-
Logs Viewer
-
Monitoring Viewer
-
Storage Admin
-
Storage Object Viewer
-
Viewer
-
Pub/Sub Viewer
-
Click Continue.
-
Click Done.
-
Click on your newly provisioned service account.
-
Click the Keys tab on the top bar.
-
Click Add Key > Create new key.
-
On the Create private key for "splunk-ta" page, leave the default JSON key type selected and click Create. This will download the JSON key file to your system - store this for later.
CLI
- Create the service account:
- Give the correct permissions:
- Create and download the service key JSON:
Click Check my progress to verify the objective.
Add JSON credential to GCP-TA
- Open the Splunk Cloud console in a new browser tab.
- Under Apps, select Splunk Add-on for Google Cloud Platform.
- Click on Configuration.
- Under the Google Credentials tab, click on Add.
- On the Add Google Credentials page, type
gcp_credsin the Name field and paste the credentials from the JSON file that was downloaded when you created the service account in the Google Service Account Credentials field. - Then click Add.
If you encounter an invalid JSON error, verify that you haven't pasted any additional carriage returns (line ending) in the private key. If you copy the text from a terminal it may lead to extra lines. The private_key should be a single line that will line wrap in the UI.
Explore GCP-TA Inputs
-
Click on Inputs.
-
Expand the Create New Input dropdown menu.
You should see the different options, including Cloud Pub/Sub, Cloud Monitoring, Google Cloud BigQuery Billing, Cloud Storage Bucket, and Resource Metadata.
The table below details their purposes.
|
Input |
Purpose |
|
Cloud Pub/Sub |
Logging events and other Pub/Sub generated events |
|
Cloud Monitor |
Metrics such as CPU and DISK usages of Instances. |
|
Google Cloud BigQuery Billing |
Pull billing information from a Cloud Storage bucket. Note, this doesn't work currently work for everyone due to the decomissioning of File Export for Billing (only billing accounts with previous CSV configuration will work). |
|
Cloud Storage Bucket |
Pulls data from a Cloud Storage bucket such as application logs but could be any CSV, JSON or raw text. |
|
Resource Metadata |
Information on the resources in an organization/project. |
The Splunk Add-on for Google Cloud supports ingesting a variety of data sources from Google Cloud. You've already set up Dataflow to send Google Cloud logs to Splunk, so next you'll configure the Splunk TA to pull:
- Resource Metadata
- Cloud Monitoring
Resource Metadata
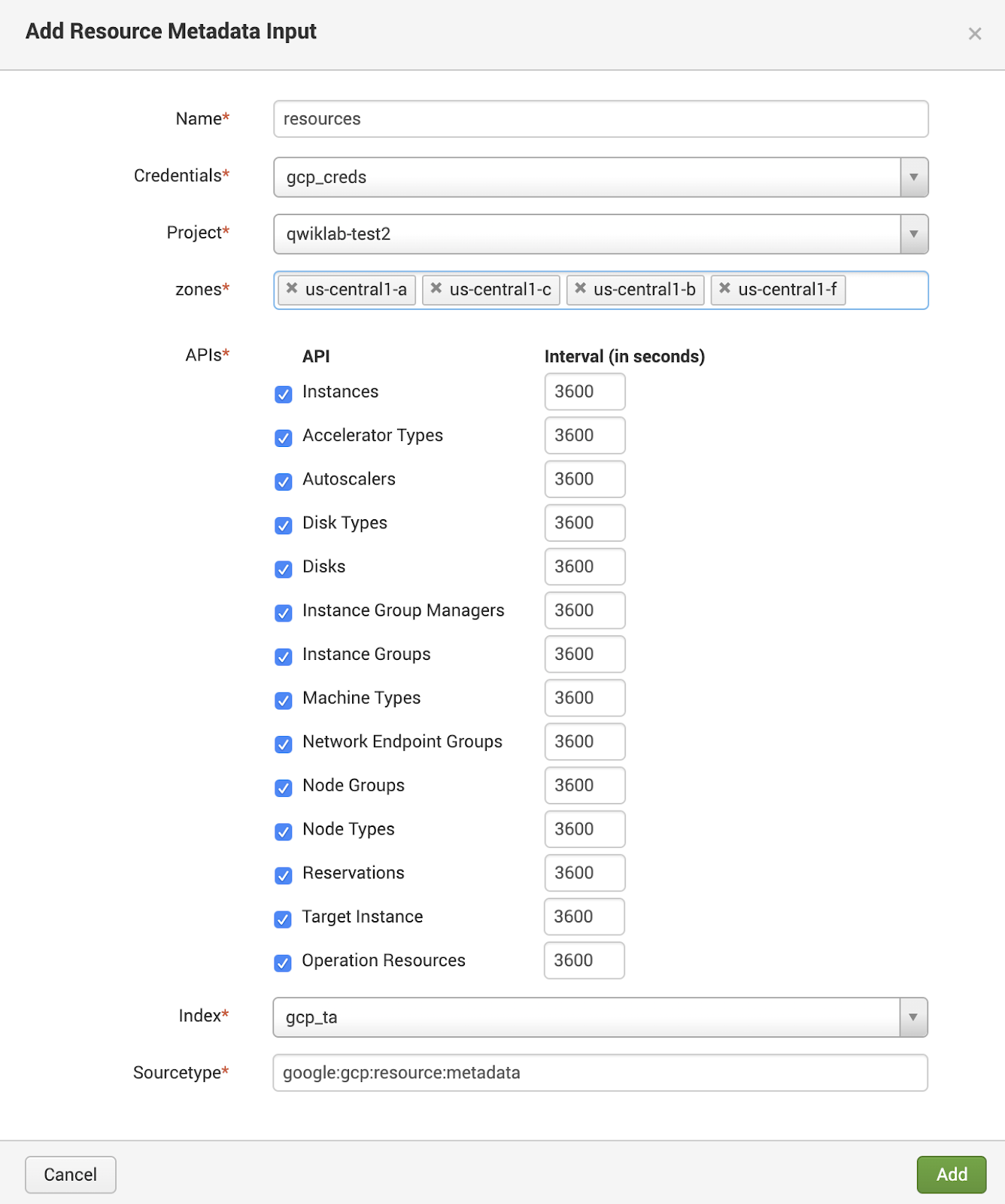
The Resource Metadata input can be configured to pull metadata from various Compute Engine resources and enable Splunk users to monitor and set up analytics for their Compute Engine deployments.
-
Click Create New Input > Resource Metadata > Compute Engine.
-
Configure a Resource Metadata input with the following (again, each project will be unique):
|
Name |
|
|
Credentials |
select the |
|
Project |
<your-project-id> |
|
Zones |
us-central1-a, b, c, f |
|
APIs |
leave all checked |
|
Index |
|
|
Sourcetype |
keep default |
Your configuration should resemble the following:
- Click Add.
Cloud Monitoring
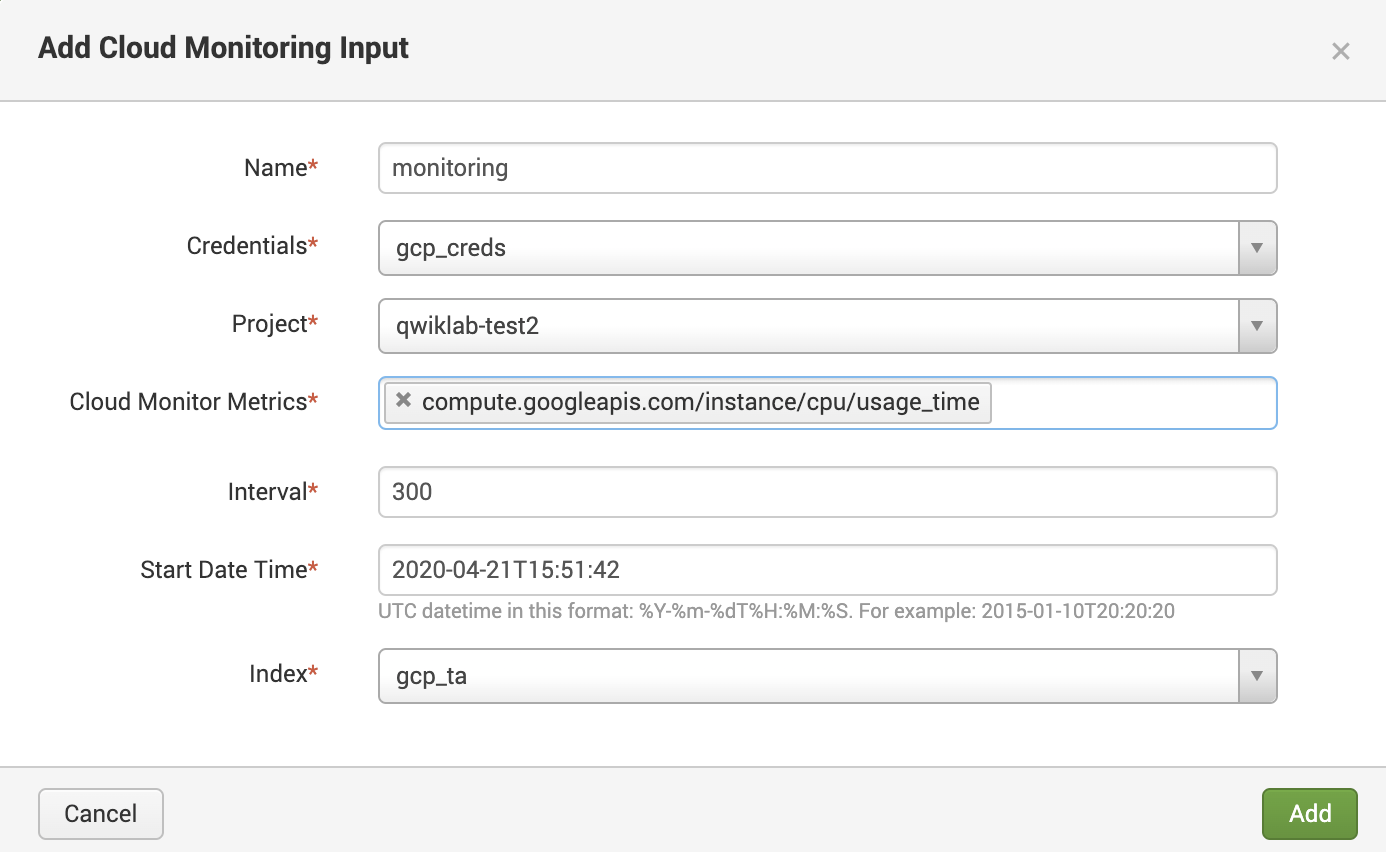
Cloud Monitoring collects metrics from a wide range of services on Google Cloud, as well as a variety of third-party software. A complete list of all predefined metrics can be found in the Metrics list reference. If you need something that isn't already defined, you can create your own custom metrics.
-
Click Create New Input > Cloud Monitoring.
-
Configure Cloud Monitoring Input with the following parameters:
|
Name |
|
|
Credentials |
select the |
|
Project |
<your-project-id> |
|
Cloud Monitor Metrics |
compute.googleapis.com/instance/cpu/usage_time |
|
Interval |
keep default |
|
Start Date Time |
keep default |
|
Index |
|
Your configuration should resemble the following:
- Click Add.
Bonus - Pub/Sub Input
This section requires usage of the CLI. Ensure the environment variables provided in the Setup section of this lab are present in your shell.
You can also ingest logs via the Pub/Sub input using the TA.
- To do this, run the following command in Cloud Shell to create a second subscription to the original Pub/Sub topic previously created. In this case, it's called
ta_subscription:
- Then you'll have to give the TA service account explicit subscriber access to the subscription you created:
Click Check my progress to verify the objective.
-
Finally, navigate back to the Splunk Cloud console.
-
Click Create New Input > Cloud Pub/Sub.
-
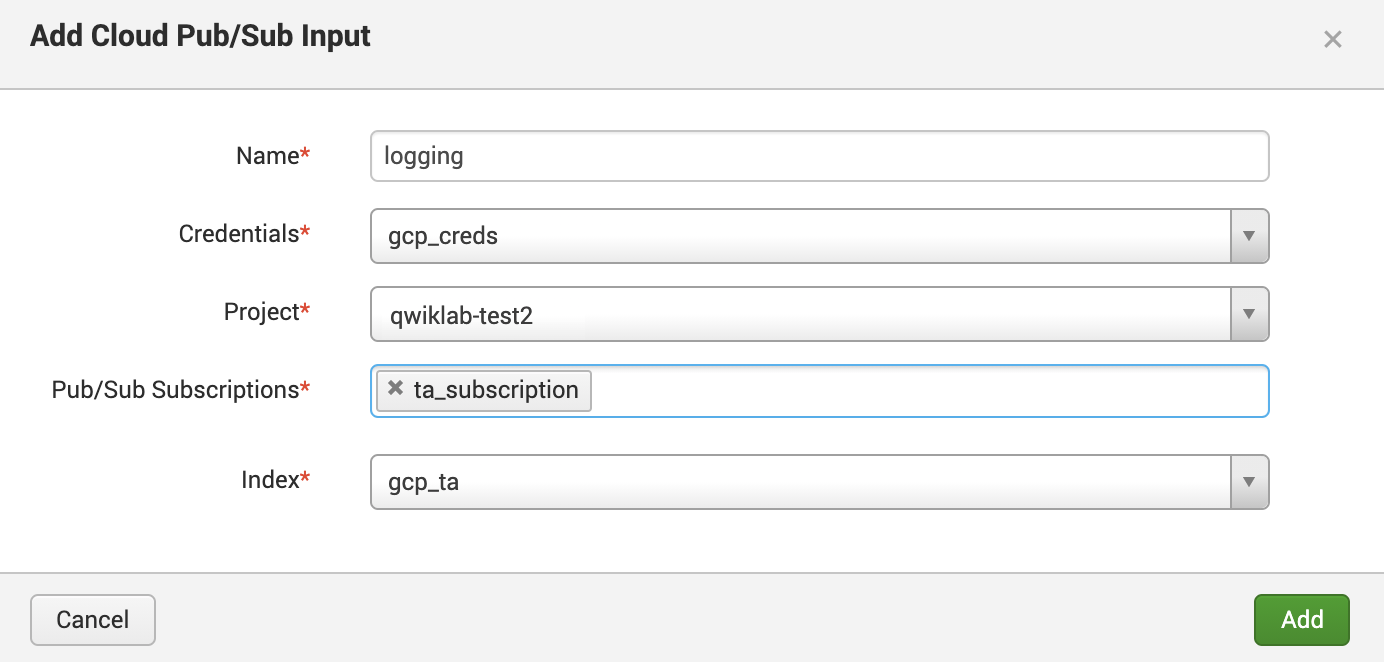
Fill out the configuration as follows, you can add the Cloud Pub/Sub input pointing to the subscription created:
|
Name |
|
|
Credentials |
select the |
|
Project |
<your-project-id> |
|
Pub/Sub Subscriptions |
|
|
Index |
|
Your configuration should resemble the following:
Task 7. Sample searches
Now that you have various types of Google Cloud data hooked up to Splunk, take a look at some common Splunk searches you can use to get value out of this data.
- First, from the top navigation bar navigate to Apps > Search & Reporting.
Who is exporting JSON credential keys?
- Copy/paste the following in the search box:
What service accounts have been created and by whom?
This SPL will generate a table of those events.
- Copy/paste the following in the search box:
Display instances in the project
- Copy/paste the following in the search box:
Task 8. Monitor and troubleshoot pipelines
While Splunk can be used for most troubleshooting scenarios, there is one situation where that cannot be done: when Dataflow has failed to send data to Splunk. To troubleshoot and monitor in these situations you'll have to rely on the built-in monitoring and logging in the Google Cloud console.
Monitoring Dataflow via Operations Monitor Dashboard
This section requires usage of the CLI. Ensure the environment variables provided in the Setup section of this lab are present in your shell.
- Navigate to Navigation menu > Monitoring > Dashboards in the Cloud Console.
The first time the monitoring console is opened it may prompt you to either create a new workspace (default select) or to add it to an existing workspace.
-
Accept the default select and click on Add.
-
Once the workspace has been prepared, open Cloud Shell and run the following to deploy a custom dashboard. You're free to edit and tweak the dashboards:
-
Go back to dashboards. You should see a dashboard in the list called Splunk Dataflow Export Monitor. If you don't, refresh the webpage.
-
After some time you should see the metrics for the Dataflow and Pub/Sub jobs.
Click Check my progress to verify the objective.
Finding errors in Dataflow jobs
-
To see errors in Dataflow you can open up the Dataflow job by going to Navigation menu > Analytics > Dataflow > Jobs and clicking on the running job.
-
At the bottom of the page you can click on either Job Logs or Worker Logs to see logging relating to either the deployment and running of the stream itself (Job Logs) or logging relating to the function of the workers individually (Worker Logs).
Task 9. Comparison of methods
In this lab you've seen two different ways to ingest logging data into Splunk.
The following table compares each method:
|
Method |
Pro |
Con |
|
Splunk Add-on for Google Cloud (TA) |
|
|
|
Dataflow |
|
|
Task 10. (Optional) Online Boutique Demo
This section requires usage of the CLI. Ensure the environment variables provided in the Setup section of this lab are present in your shell.
The Online Boutique Demo deploys numerous microservices and a simulated work log that will generate realistic log entries that you'll be able to inspect in Splunk. Refer to the GitHub repo for full details as to what is getting deployed.
Build GKE cluster
- Enable required services:
- Create a GKE cluster and verify nodes creation. This process can take about 2 minutes:
- Configure gcloud for docker auth:
Install boutique
- Clone the Online Boutique shop demo repository:
- Deploy using pre-built container images:
- Get the external IP of the Online Boutique once deployed:
The deployment can take a few minutes to fully spin up and show the external IP.
Install Splunk Connect for Kubernetes (SC4K)
In the next few steps you will configure Splunk Connect for Kubernetes to send data to HEC. While much of this logging information is available via the standard Google Cloud logging, SC4K can provide deeper insight and allow Kubernetes visibility outside of Google Cloud.
- First, create a namespace for the SC4K pods:
- Add the SC4K repo to helm:
- Create a YAML file for the SC4K configuration:
- Install Splunk Connect for Kubernetes via the Helm Chart:
Explore boutique logs
Data should now be streaming into Splunk. Here's a couple of samples searches:
- Average response time by request path:
- See the type of metrics that are being reported:
Congratulations!
In this lab you used the Splunk Add-on for Google Cloud to create Splunk indexes, HTTP Event Collectors (HECs), log sinks, Cloud Storage buckets, and create Pub/Sub topics and subscriptions. You then launched a Dataflow template deployment, configure GCP-TA inputs, performed sample Splunk searches across ingested data, and monitored and troubleshooted Dataflow pipelines.
Next steps / learn more
Check out the following for more information on Splunk with Google Cloud:
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated July 28, 2023
Lab Last Tested July 28, 2023
Creator Content available herein, is owned by Splunk Inc. and is provided "AS IS" without warranty of any kind.
Splunk, Splunk>, Turn Data Into Doing, Data-to-Everything and D2E are trademarks or registered trademarks of Splunk Inc. in the United States and other countries. All other brand names, product names, or trademarks belong to their respective owners. © 2021 Splunk Inc. All rights reserved.
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.